| 【強化學(xué)習(xí)】近端策略優(yōu)化算法(PPO)萬字詳解(附代碼) | 您所在的位置:網(wǎng)站首頁 › 算卦有什么算法和方法 › 【強化學(xué)習(xí)】近端策略優(yōu)化算法(PPO)萬字詳解(附代碼) |
【強化學(xué)習(xí)】近端策略優(yōu)化算法(PPO)萬字詳解(附代碼)
|
??????????本篇文章是博主強化學(xué)習(xí)(RL)領(lǐng)域?qū)W習(xí)時,用于個人學(xué)習(xí)、研究或者欣賞使用,并基于博主對相關(guān)等領(lǐng)域的一些理解而記錄的學(xué)習(xí)摘錄和筆記,若有不當(dāng)和侵權(quán)之處,指出后將會立即改正,還望諒解。文章分類在??強化學(xué)習(xí)專欄: ? ? ? ?【強化學(xué)習(xí)】- 【單智能體強化學(xué)習(xí)】(9)---《近端策略優(yōu)化算法(PPO)詳解》 近端策略優(yōu)化算法(PPO)詳解目錄 PPO算法介紹 1. 背景 2. PPO 的核心思想 3. PPO 流程 4. 為什么 PPO 很強? 5. PPO 的直觀類比 PPO算法的流程推導(dǎo)及數(shù)學(xué)公式 1. 背景與目標(biāo) 2. PPO的概率比率 3. 優(yōu)化目標(biāo) 4. 值函數(shù)優(yōu)化 5. 策略熵正則化 6. 總損失函數(shù) 7. PPO 算法流程 8.PPO算法的關(guān)鍵 [Python] PPO算法的代碼實現(xiàn) 逐行解釋 PPO 代碼和公式 1. Actor-Critic 神經(jīng)網(wǎng)絡(luò) 2. Memory 類 3. PPO 初始化 4. 動作選擇 5. 策略更新 7.主程序 [Notice]?代碼解釋 總結(jié) PPO算法、TRPO算法 和 A3C算法對比 PPO算法介紹? ? ? ? 近端策略優(yōu)化、PPO(Proximal Policy Optimization)是一種強化學(xué)習(xí)算法,設(shè)計的目的是在復(fù)雜任務(wù)中既保證性能提升,又讓算法更穩(wěn)定和高效。以下用通俗易懂的方式介紹其核心概念和流程。 1. 背景????????PPO 是 OpenAI 在 2017 年提出的一種策略優(yōu)化算法,專注于簡化訓(xùn)練過程,克服傳統(tǒng)策略梯度方法(如TRPO)的計算復(fù)雜性,同時保證訓(xùn)練效果。 問題:在強化學(xué)習(xí)中,直接優(yōu)化策略會導(dǎo)致不穩(wěn)定的訓(xùn)練,模型可能因為過大的參數(shù)更新而崩潰。解決方案:PPO通過限制策略更新幅度,使得每一步訓(xùn)練都不會偏離當(dāng)前策略太多,同時高效利用采樣數(shù)據(jù)。 2. PPO 的核心思想PPO 的目標(biāo)是通過以下方式改進策略梯度優(yōu)化: 限制策略更新幅度,防止策略過度偏離。使用優(yōu)勢函數(shù)
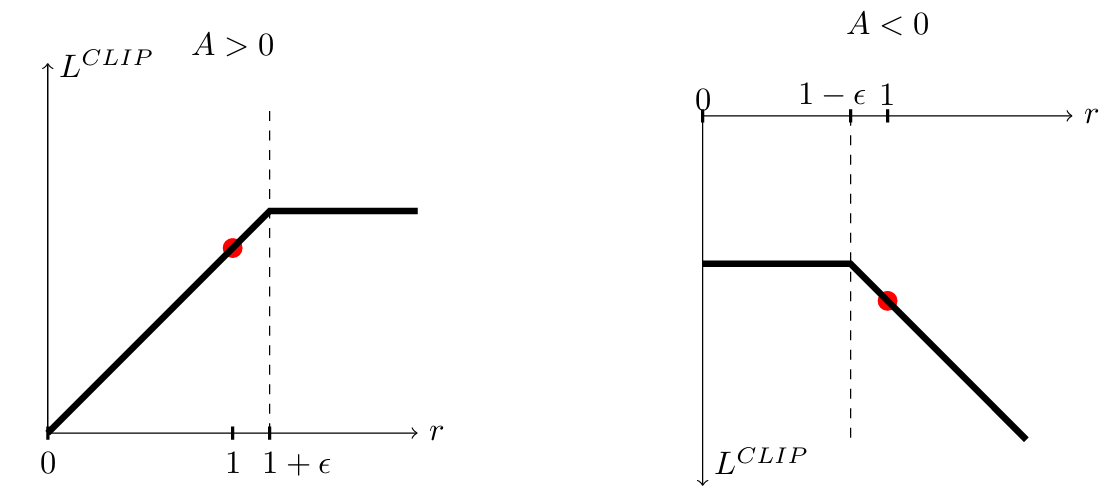
PPO 的目標(biāo)函數(shù)如下: 其中:
剪輯作
假設(shè)你是一個籃球教練,訓(xùn)練球員投籃: 如果每次訓(xùn)練完全改變投籃動作,球員可能會表現(xiàn)失常(類似于策略更新過度)。如果每次訓(xùn)練動作變化太小,可能很難進步(類似于更新不足)。PPO 的剪輯機制就像一個“適度改進”的規(guī)則,告訴球員在合理范圍內(nèi)調(diào)整投籃動作,同時評估每次投籃的表現(xiàn)是否優(yōu)于平均水平。 PPO算法的流程推導(dǎo)及數(shù)學(xué)公式????????PPO(Proximal Policy Optimization)也是一種策略優(yōu)化算法,它的核心思想是對策略更新進行限制,使訓(xùn)練更加穩(wěn)定,同時保持效率。以下是其數(shù)學(xué)公式推導(dǎo)和整體流程: 1. 算法目標(biāo)????????強化學(xué)習(xí)的核心目標(biāo)是優(yōu)化策略 目標(biāo)是優(yōu)化以下期望: 通過梯度上升法更新策略。 2. PPO的概率比率PPO在優(yōu)化過程中引入了概率比率,用于衡量新舊策略的差異: 這個比率表示策略變化的程度。 3. 優(yōu)化目標(biāo)為了限制策略的更新幅度,PPO引入了剪輯目標(biāo)函數(shù): PPO的目標(biāo)是找到一個折中:在保持改進的同時防止策略變化過大。 4. 值函數(shù)優(yōu)化PPO不僅優(yōu)化策略,還同時更新值函數(shù) 這個損失函數(shù)使得Critic能夠更準(zhǔn)確地估計狀態(tài)值。 5. 策略熵正則化為了鼓勵策略的探索,PPO引入了熵正則化項: PPO結(jié)合策略損失、值函數(shù)損失和熵正則化項,形成總損失函數(shù): PPO 可以簡化為以下步驟: 采樣: 使用當(dāng)前策略 計算優(yōu)勢函數(shù): 評估某個動作計算概率比率 策略更新: 如果更新過大(超出剪輯范圍值函數(shù)更新: 用以下?lián)p失函數(shù)優(yōu)化值函數(shù) 重復(fù)以上步驟: 通過多輪迭代,使策略逐步優(yōu)化,直到收斂。 8.PPO算法的關(guān)鍵PPO的關(guān)鍵公式和目標(biāo)可以概括如下: 核心目標(biāo):?優(yōu)化策略,使這種設(shè)計使得PPO在訓(xùn)練過程中高效且穩(wěn)定,是目前強化學(xué)習(xí)中的常用算法之一。 [Python] PPO算法的代碼實現(xiàn)以下是使用 PyTorch 實現(xiàn) PPO(Proximal Policy Optimization)算法的完整代碼 ?項目代碼我已經(jīng)放入GitCode里面,可以通過下面鏈接跳轉(zhuǎn):?? 【強化學(xué)習(xí)】---PPO算法? 后續(xù)相關(guān)單智能體強化學(xué)習(xí)算法也會不斷在【強化學(xué)習(xí)】項目里更新,如果該項目對你有所幫助,請幫我點一個星星?????,鼓勵分享,十分感謝!!! 若是下面代碼復(fù)現(xiàn)困難或者有問題,也歡迎評論區(qū)留言。 """《PPO算法的代碼》 時間:2024.12 環(huán)境:gym 作者:不去幼兒園 """ import torch # Import PyTorch, a popular machine learning library import torch.nn as nn # Import the neural network module import torch.optim as optim # Import optimization algorithms from torch.distributions import Categorical # Import Categorical for probabilistic action sampling import numpy as np # Import NumPy for numerical computations import gym # Import OpenAI Gym for environment simulation 逐行解釋 PPO 代碼和公式以下是對實現(xiàn)的 PyTorch PPO 算法代碼 的詳細解釋,逐行結(jié)合公式解析: 1. Actor-Critic 神經(jīng)網(wǎng)絡(luò) # Define Actor-Critic Network class ActorCritic(nn.Module): # Define the Actor-Critic model def __init__(self, state_dim, action_dim): # Initialize with state and action dimensions super(ActorCritic, self).__init__() # Call parent class constructor self.shared_layer = nn.Sequential( # Shared network layers for feature extraction nn.Linear(state_dim, 128), # Fully connected layer with 128 neurons nn.ReLU() # ReLU activation function ) self.actor = nn.Sequential( # Define the actor (policy) network nn.Linear(128, action_dim), # Fully connected layer to output action probabilities nn.Softmax(dim=-1) # Softmax to ensure output is a probability distribution ) self.critic = nn.Linear(128, 1) # Define the critic (value) network to output state value def forward(self, state): # Forward pass for the model shared = self.shared_layer(state) # Pass state through shared layers action_probs = self.actor(shared) # Get action probabilities from actor network state_value = self.critic(shared) # Get state value from critic network return action_probs, state_value # Return action probabilities and state value shared_layer:?將狀態(tài) ?s ?映射到一個隱層表示,使用 ReLU 激活函數(shù)。actor:?輸出策略其中 用于存儲一個 episode 的經(jīng)驗數(shù)據(jù): states: 狀態(tài)、actions: 動作、logprobs: 動作的對數(shù)概率、rewards: 即時獎勵 、is_terminals: 是否為終止?fàn)顟B(tài)(布爾值) 作用:為后續(xù)策略更新提供樣本數(shù)據(jù)。 3. PPO 初始化 # PPO Agent class PPO: # Define the PPO agent def __init__(self, state_dim, action_dim, lr=0.002, gamma=0.99, eps_clip=0.2, K_epochs=4): self.policy = ActorCritic(state_dim, action_dim).to(device) # Initialize the Actor-Critic model self.optimizer = optim.Adam(self.policy.parameters(), lr=lr) # Adam optimizer for parameter updates self.policy_old = ActorCritic(state_dim, action_dim).to(device) # Copy of the policy for stability self.policy_old.load_state_dict(self.policy.state_dict()) # Synchronize parameters self.MseLoss = nn.MSELoss() # Mean Squared Error loss for critic updates self.gamma = gamma # Discount factor for rewards self.eps_clip = eps_clip # Clipping parameter for PPO self.K_epochs = K_epochs # Number of epochs for optimization policy:?當(dāng)前策略網(wǎng)絡(luò),用于輸出動作概率和狀態(tài)值。policy_old:?舊策略網(wǎng)絡(luò),用于計算概率比率6. Surrogate Loss # Update for K epochs for _ in range(self.K_epochs): # Get action probabilities and state values action_probs, state_values = self.policy(old_states) # Get action probabilities and state values dist = Categorical(action_probs) # Create a categorical distribution new_logprobs = dist.log_prob(old_actions) # Compute new log probabilities of actions entropy = dist.entropy() # Compute entropy for exploration # Calculate ratios ratios = torch.exp(new_logprobs - old_logprobs.detach()) # Compute probability ratios # Advantages advantages = rewards - state_values.detach().squeeze() # Compute advantages # Surrogate loss surr1 = ratios * advantages # Surrogate loss 1 surr2 = torch.clamp(ratios, 1 - self.eps_clip, 1 + self.eps_clip) * advantages # Clipped loss loss_actor = -torch.min(surr1, surr2).mean() # Actor loss # Critic loss loss_critic = self.MseLoss(state_values.squeeze(), rewards) # Critic loss # Total loss loss = loss_actor + 0.5 * loss_critic - 0.01 * entropy.mean() # Combined loss # Update policy self.optimizer.zero_grad() # Zero the gradient buffers loss.backward() # Backpropagate loss self.optimizer.step() # Perform a parameter update # Update old policy self.policy_old.load_state_dict(self.policy.state_dict()) # Copy new policy parameters to old policy 比率:Actor-Critic 網(wǎng)絡(luò)結(jié)構(gòu): ? ?ActorCritic?模型通過共享層生成動作概率和狀態(tài)值。 PPO 的優(yōu)化目標(biāo): ????????使用裁剪的目標(biāo)函數(shù)限制策略更新幅度,避免過度更新。 ? ?state_values?通過 Critic 網(wǎng)絡(luò)提供狀態(tài)價值的估計。 內(nèi)存存儲: ? ?Memory?用于存儲每一輪的狀態(tài)、動作、獎勵和終止標(biāo)志。 策略更新: ????????通過多個 epoch 更新,計算?優(yōu)勢函數(shù)?和?裁剪后的策略梯度。 獎勵歸一化: ????????使用標(biāo)準(zhǔn)化方法對獎勵進行處理,以加快收斂。 訓(xùn)練循環(huán): ????????PPO 從環(huán)境中采樣,更新策略,打印每一集的總獎勵。 ?# 環(huán)境配置 Python 3.11.5 torch 2.1.0 torchvision 0.16.0 gym 0.26.2????????由于博文主要為了介紹相關(guān)算法的原理和應(yīng)用的方法,缺乏對于實際效果的關(guān)注,算法可能在上述環(huán)境中的效果不佳或者無法運行,一是算法不適配上述環(huán)境,二是算法未調(diào)參和優(yōu)化,三是沒有呈現(xiàn)完整的代碼,四是等等。上述代碼用于了解和學(xué)習(xí)算法足夠了,但若是想直接將上面代碼應(yīng)用于實際項目中,還需要進行修改。 總結(jié)????????PPO 的關(guān)鍵是通過限制策略的變化范圍(剪輯),讓優(yōu)化更加穩(wěn)定,同時通過優(yōu)勢函數(shù)引導(dǎo)策略改進,充分利用采樣數(shù)據(jù)。這種平衡使得 PPO 成為許多強化學(xué)習(xí)任務(wù)的默認算法。 ?更多強化學(xué)習(xí)文章,請前往:【強化學(xué)習(xí)(RL)】專欄 PPO算法、TRPO算法 和 A3C算法對比????????以下是 PPO算法、TRPO算法 和 A3C算法 的區(qū)別分析: 特性PPO (Proximal Policy Optimization)TRPO (Trust Region Policy Optimization)A3C (Asynchronous Advantage Actor-Critic)核心思想使用裁剪的目標(biāo)函數(shù),限制策略更新幅度,保持穩(wěn)定性和效率。限制策略更新的步幅(Trust Region),通過二次約束優(yōu)化確保穩(wěn)定性。通過異步多線程運行環(huán)境并行采樣和訓(xùn)練,降低方差并加快收斂速度。優(yōu)化目標(biāo)函數(shù)引入剪輯機制通過KL散度限制策略更新優(yōu)化策略梯度更新方式同步更新,支持多輪迭代更新樣本數(shù)據(jù)以提高效率。同步更新,通過優(yōu)化約束的目標(biāo)函數(shù)嚴格限制更新步長。異步更新,多個線程獨立采樣和更新全局模型。計算復(fù)雜度低,計算簡單,使用裁剪避免復(fù)雜的二次優(yōu)化問題。高,涉及二次優(yōu)化問題,計算復(fù)雜,資源需求較大。較低,依賴異步線程并行計算,資源利用率高。樣本利用率高效,可重復(fù)利用采樣數(shù)據(jù)進行多輪梯度更新。高效,嚴格優(yōu)化目標(biāo),提升了樣本效率。較低,因為每個線程獨立運行,可能導(dǎo)致數(shù)據(jù)重復(fù)和冗余。實現(xiàn)難度中等,使用簡單的裁剪方法,適合大多數(shù)場景。高,涉及復(fù)雜的約束優(yōu)化和實現(xiàn)細節(jié)。較低,直接異步實現(xiàn),簡單易用。收斂速度快,因裁剪機制限制更新幅度,能快速穩(wěn)定收斂。慢,因嚴格的步幅限制,收斂穩(wěn)定但需要較多訓(xùn)練迭代。快,因多線程并行采樣,能夠顯著減少訓(xùn)練時間。穩(wěn)定性高,裁剪機制限制過大更新,避免不穩(wěn)定行為。高,嚴格限制更新步幅,保證策略穩(wěn)定改進。較低,異步更新可能導(dǎo)致收斂不穩(wěn)定(如策略沖突)。應(yīng)用場景廣泛使用,適合大規(guī)模環(huán)境或復(fù)雜問題。適合需要極高穩(wěn)定性的場景,如機器人控制等。適合資源受限的場景或需要快速實驗的任務(wù),如強化學(xué)習(xí)基準(zhǔn)測試。優(yōu)點簡單易實現(xiàn),收斂快,穩(wěn)定性高,是主流強化學(xué)習(xí)算法。理論支持強,更新步幅嚴格受控,策略非常穩(wěn)定。異步更新高效,能夠充分利用多線程資源,加速訓(xùn)練。缺點理論支持弱于TRPO,可能過于保守。實現(xiàn)復(fù)雜,計算資源需求高,更新速度慢。異步更新可能導(dǎo)致訓(xùn)練不穩(wěn)定,樣本利用率較低。論文來源Schulman et al.,?"Proximal Policy Optimization Algorithms"?(2017)Schulman et al.,?"Trust Region Policy Optimization"?(2015)Mnih et al.,?"Asynchronous Methods for Deep Reinforcement Learning"?(2016) 三種算法的對比總結(jié): PPO 是 TRPO 的改進版:PPO 使用簡單的裁剪機制代替了 TRPO 的二次優(yōu)化,顯著降低了實現(xiàn)復(fù)雜度,同時保持了良好的穩(wěn)定性和效率。A3C 的并行化設(shè)計:A3C 的核心是通過多線程異步更新提升效率,但其穩(wěn)定性略低于 PPO 和 TRPO。實用性:PPO 因其簡單、穩(wěn)定、高效的特點,已成為強化學(xué)習(xí)領(lǐng)域的主流算法;TRPO 更適合需要極高策略穩(wěn)定性的任務(wù);A3C 在資源受限的場景下表現(xiàn)優(yōu)異。????????博客都是給自己看的筆記,如有誤導(dǎo)深表抱歉。文章若有不當(dāng)和不正確之處,還望理解與指出。由于部分文字、圖片等來源于互聯(lián)網(wǎng),無法核實真實出處,如涉及相關(guān)爭議,請聯(lián)系博主刪除。如有錯誤、疑問和侵權(quán),歡迎評論留言聯(lián)系作者,或者添加VX:Rainbook_2,聯(lián)系作者。? |
【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |