| 結(jié)構(gòu)方程模型處理二階混合型(反映性+形成性)構(gòu)念的方法 | 您所在的位置:網(wǎng)站首頁 › 屬龍的人牛年的運(yùn)勢(shì)及運(yùn)程 › 結(jié)構(gòu)方程模型處理二階混合型(反映性+形成性)構(gòu)念的方法 |
結(jié)構(gòu)方程模型處理二階混合型(反映性+形成性)構(gòu)念的方法
|
1. 結(jié)構(gòu)方程模型
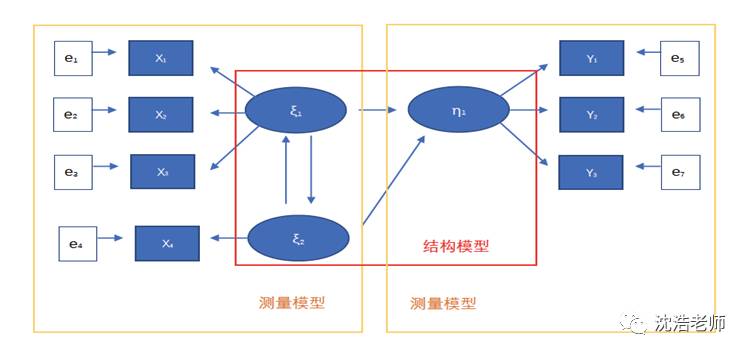
1.1 測(cè)量模型與結(jié)構(gòu)模型
(1)模型必須是因果路徑模型 (2)每一個(gè)潛變量至少應(yīng)該和另一個(gè)潛變量相關(guān) (3)每個(gè)潛變量至少需要一個(gè)觀測(cè)變量 (4)每一個(gè)觀察變量至少存在于一個(gè)潛變量上 (5)模型中只能存在一個(gè)結(jié)構(gòu)模型 2. 形成性指標(biāo)與反映性指標(biāo) 2.1 反應(yīng)型指標(biāo)在傳統(tǒng)的SEM中,觀測(cè)變量與潛變量之間為線性函數(shù)關(guān)系,潛變量的意義通過觀測(cè)變量反映,潛變量的變化會(huì)導(dǎo)致觀測(cè)標(biāo)量的變化。(X1表示觀測(cè)變量,e1表示誤差,ξ1表示潛變量,λ1表示系數(shù)),傳統(tǒng)的測(cè)量模型(反映性模型)可以用下式表達(dá):
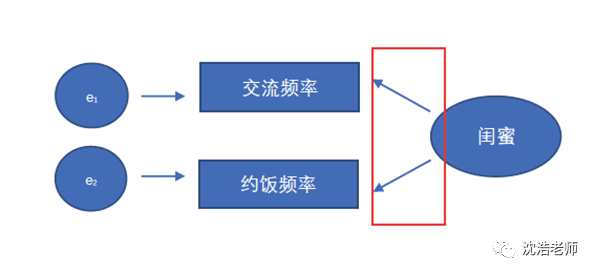
這類模型就被稱為反映性測(cè)量模型(Reflective Measurement Model),相應(yīng)的觀測(cè)變量即為反映性指標(biāo)(Reflective Indicator)。舉個(gè)例子:鑒定兩個(gè)女生是否為閨蜜,就反映在她倆交流頻率與約飯頻率等方面。
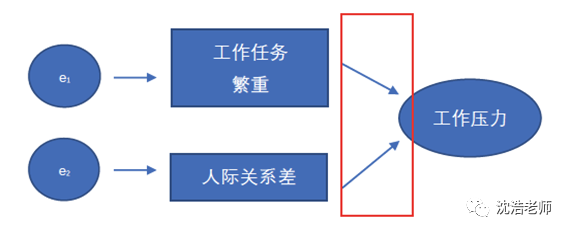
有些時(shí)候,潛變量的意義是由測(cè)量變量來決定的,這一類測(cè)量模型就稱為形成性測(cè)量模型(Formative Measurement Model),所對(duì)應(yīng)的測(cè)量變量即為形成性指標(biāo)(Formative Indicator)。舉個(gè)例子:工作任務(wù)繁重,人際關(guān)系差等造成了工作壓力。
ps:項(xiàng)目選擇和量表評(píng)價(jià)必須考慮指標(biāo)和潛變量間的方向性,應(yīng)該采用形成性測(cè)量模型而不假思索的使用反映性測(cè)量模型將會(huì)嚴(yán)重影響量表的結(jié)構(gòu)效度(Construct Vadility)和潛在構(gòu)念的屬性。 2.3 如何區(qū)分形成性模型與反映性模型第一,指標(biāo)是定義建構(gòu)的特征還是建構(gòu)的外在表現(xiàn)。如果指標(biāo)所定義的特征聯(lián)合起來解釋建構(gòu)的意義,那么形成性模型是合適的。如果指標(biāo)是由構(gòu)念決定的,那么應(yīng)選擇反映性模型。換句話說,可以通過判斷潛在構(gòu)念的變化引起指標(biāo)的變化還是指標(biāo)的變化引起潛在構(gòu)念的變化來判斷反映性模型還是形成性模型。 第二,指標(biāo)是否可在概念上互換。如果是反映性指標(biāo),它們反映的是共同的主題,任何一個(gè)條目都是建構(gòu)內(nèi)容的實(shí)質(zhì)性體現(xiàn),所以可以互換。在心理測(cè)量學(xué)中,反映性指標(biāo)其實(shí)就是一組行為樣本,而形成性指標(biāo)則不是。形成性指標(biāo)之間并不必然含有共同成分,所以形成性指標(biāo)捕捉了建構(gòu)的獨(dú)特部分,不能互換。 第三,指標(biāo)是否彼此共變。反映性模型明確預(yù)示指標(biāo)間彼此高相關(guān),而形成性模型并沒有這樣的預(yù)測(cè),它們之間即可以高相關(guān),也可以低相關(guān),甚至其他任何的相關(guān)形式。 最后,所有的指標(biāo)是否具有相同的前因或/和后果。反映性指標(biāo)反映相同的潛在構(gòu)念所以它們具有相同的前因或/和后果。然而,形成性指標(biāo)彼此不能相互替代,并且僅代表構(gòu)念領(lǐng)域的特有部分,所以它們有著不同的前因和/或后果。 2.4 帶形成性指標(biāo)的例子
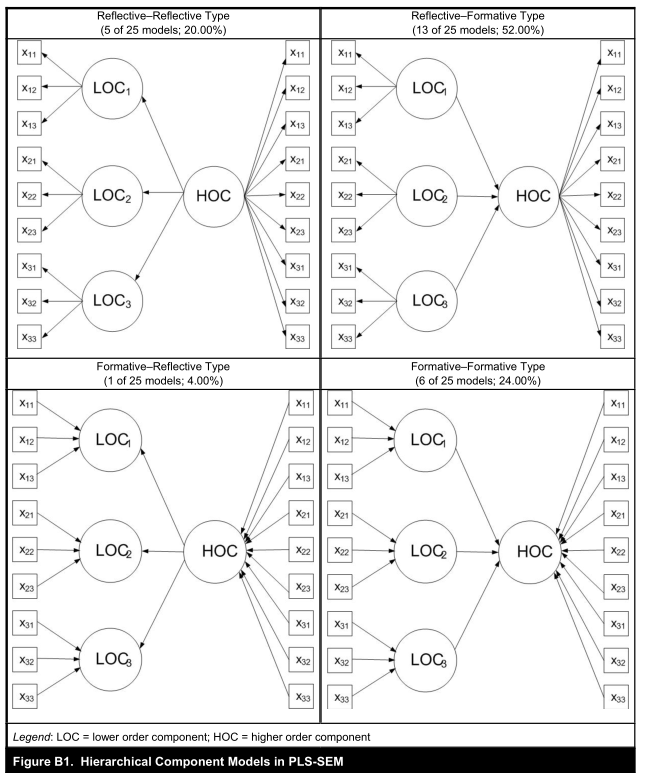
參考:A Critical Look at the Use of PLS-SEM in MIS Quarterly 附錄B 3.1 指標(biāo)重用高階潛變量可使用低階潛變量的所有指標(biāo)作為其指標(biāo),當(dāng)?shù)碗A潛具有相同的指標(biāo)數(shù)量時(shí)這種方法效果最好,否則對(duì)低階和高階成分之間關(guān)系的解釋必須考慮到較低階組成部分中不等數(shù)量指標(biāo)的偏差。該問題的潛在解決方案是計(jì)算和比較低階分量指標(biāo)和高階分量之間的總效應(yīng)。 如圖,高階變量使用了低階變量的指標(biāo)
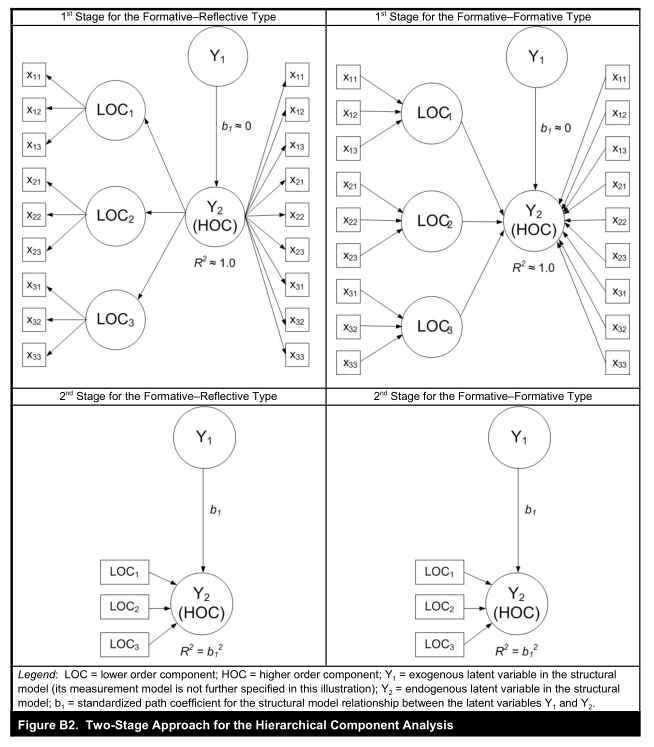
如下圖,當(dāng)使用重復(fù)指標(biāo)方法時(shí),這些模型設(shè)置需要特別注意,因?yàn)楦唠A分量的幾乎所有方差都由其低階分量(LOC1-3)(R2=1.0;圖B2)解釋。 因此,從潛變量到內(nèi)生高階分量的路徑關(guān)系總是近似為零且不顯著(Y1不顯著)。 當(dāng)遇到這種問題的時(shí)候,為了得到低階潛變量到高階潛變量的得分,可使用兩階段法,在第一階段,人們使用重復(fù)指標(biāo)方法來獲得低階分量的潛在變量分?jǐn)?shù),然后在第二階段中,作為高階分量的測(cè)量模型中的顯性變量(圖B2)。 因此,高階分量以允許其他潛在變量作為前驅(qū)的方式嵌入在法則網(wǎng)中,以解釋其一些方差,這可能導(dǎo)致顯著的路徑關(guān)系。 (換種說法,第一階段,利用indicators reuse approach,運(yùn)行PLS,得到一階因子的潛變量分?jǐn)?shù)。第二步,將一階因子的潛變量分?jǐn)?shù)作為高階變量的指標(biāo),重新運(yùn)行PLS。這樣,其他潛變量就可以解釋此高階變量的方差了,路徑系數(shù)顯著。 )
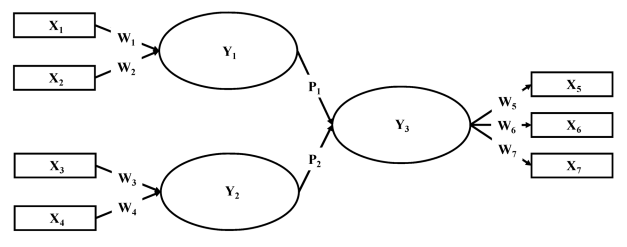
我們以下圖的模型示例來說明PLS的計(jì)算步驟:
ps:圖取自Hair, J. F., Ringle, C. M., & Sarstedt, M. 2011. PLS-SEM: Indeed a Silver Bullet. Journal of Marketing Theory and Practice, 18(2): 139-152. PS:數(shù)據(jù)先標(biāo)準(zhǔn)化 第1步:反復(fù)的估計(jì)潛在變量的得分(latent construct scores,潛在概念分?jǐn)?shù)),基本上就是去計(jì)算一個(gè)分?jǐn)?shù)來代表潛在變量(construct),你可以簡(jiǎn)單的想象,一個(gè)潛在變量(construct)通常會(huì)有三個(gè)以上的低級(jí)指標(biāo)(items)來衡量它,這代表了有一群數(shù)據(jù)反應(yīng)出該潛在變量(construct),這樣子的狀況需要一個(gè)簡(jiǎn)單的數(shù)據(jù)來展現(xiàn)潛在變量(construct),簡(jiǎn)化指標(biāo)(items)的數(shù)量(或者說是復(fù)雜度)但又可以展現(xiàn)指標(biāo)的意義。所以PLS就用了以下的一套方法來估計(jì)一個(gè)分?jǐn)?shù)給潛在變量(找對(duì)應(yīng)的權(quán)重)。 1.1步:以上圖的模型來說潛在變量(construct)Y1, Y2, Y3 的潛在變量分?jǐn)?shù)(latent construct scores)。 基本上就是使用回歸來估計(jì)每一個(gè)潛在變量(construct)的分?jǐn)?shù)(latent construct scores)。 1.2步:用剛剛得到的分?jǐn)?shù)來估計(jì)路徑系數(shù)(path coefficients),以上圖來說是要估計(jì)P1和P2。回歸算權(quán)重。 1.3步:用1.1步的Y1, Y2, Y3 的潛在變量分?jǐn)?shù)和1.2步的路徑系數(shù)來調(diào)整潛在變量得分。即是因?yàn)橹八鉟1, Y2, Y3 我們是直接用它們的低級(jí)指標(biāo)來算的,而實(shí)際上他們還由其他的變量組成,比如Y3由Y1,Y2,x5,x6,x7組成,因此用他們重新估計(jì)之前沒有考慮應(yīng)該有路徑的潛在變量得分。 1.4步: 上面的步驟已經(jīng)能獲得初步的潛在變量得分,接下來運(yùn)用這些初步獲得的得分重新去估計(jì)指標(biāo)到潛變量的權(quán)重,基本上就是重新去計(jì)算W1~7 第2步:用最小二乘法來決定最後的指標(biāo)到潛變量的權(quán)重(factor loading)和潛變量到潛變量的權(quán)重(path coefficients)估計(jì)值。簡(jiǎn)單點(diǎn)就不斷的重復(fù)上面的作直到這些權(quán)重的到一個(gè)穩(wěn)定的值,收斂。 完成以上的步驟之后,就會(huì)得到一組W1~7, P1~2, 還有每一個(gè)潛變量的得分 。記住,這些數(shù)據(jù)都只會(huì)有一個(gè),例如W1~7,就只是7個(gè)數(shù)據(jù),展現(xiàn)出權(quán)重而已。但這樣的結(jié)果并沒辦法讓你知道你的模型好不好,也沒有辦法檢驗(yàn)?zāi)愕募僬f。 5. 模型評(píng)價(jià) 5.1 基本擬合標(biāo)準(zhǔn)基本擬合標(biāo)準(zhǔn)是用來檢驗(yàn)?zāi)P偷恼`差以及誤輸入等問題。 主要包括: (1)不能有負(fù)的測(cè)量誤差; (2)測(cè)量誤差必須達(dá)到顯著性水平; (3)因子載荷必須介于0.5-0.95之間; (4)不能有很大的標(biāo)準(zhǔn)誤差。 5.2 模型內(nèi)在結(jié)構(gòu)擬合度模型的內(nèi)在結(jié)構(gòu)擬合度是用來評(píng)價(jià)模型內(nèi)估計(jì)參數(shù)的顯著程度、各指標(biāo)及潛在變量的信度。 主要包括: (1)潛變量的組成信度(CR),0.7以上表明組成信度較好; 潛變量的CR值是其所有觀測(cè)變量的信度的組合,該指標(biāo)用來分析潛變量的各觀測(cè)變量間的一致性 (2)平均提煉方差(AVE),0.5以上為可以接受的水平。 AVE用于估計(jì)測(cè)量模型的聚合效度,反映了潛變量的各觀測(cè)變量對(duì)該潛變量的平均差異解釋力,即潛變量的各觀測(cè)變量與測(cè)量誤差相比在多大程度上捕捉到了該潛變量的變化。 5.3 整體模型擬合度整體模型擬合度是用來評(píng)價(jià)模型與數(shù)據(jù)的擬合程度。 主要包括: (1)絕對(duì)擬合度,用來確定模型可以預(yù)測(cè)協(xié)方差陣和相關(guān)矩陣的程度; (2)簡(jiǎn)約擬合度,用來評(píng)價(jià)模型的簡(jiǎn)約程度; (3)增值擬合度,理論模型與虛無模型的比較。 包括: (1)χ2卡方擬合指數(shù)檢驗(yàn)選定的模型協(xié)方差矩陣與觀察數(shù)據(jù)協(xié)方差矩陣相匹配的假設(shè)。原假設(shè)是模型協(xié)方差陣等于樣本協(xié)方差陣。如果模型擬合的好,卡方值應(yīng)該不顯著。在這種情況下,數(shù)據(jù)擬合不好的模型被拒絕。 (2)RMR 是殘差均方根。RMR 是樣本方差和協(xié)方差減去對(duì)應(yīng)估計(jì)的方差和協(xié)方差的平方和,再取平均值的平方根。RMR應(yīng)該小于0.08,RMR越小,擬合越好。 (3)RMSEA 是近似誤差均方根 RMSEA應(yīng)該小于0.06,越小越好。 GFI 是擬合優(yōu)度指數(shù),范圍在0和1間,但理論上能產(chǎn)生沒有意義的負(fù)數(shù)。按照約定,要接受模型,GFI 應(yīng)該等于或大于0.90。 (4)PGFI 是簡(jiǎn)效擬合優(yōu)度指數(shù)。它是簡(jiǎn)效比率(PRATIO,獨(dú)立模式的自由度與內(nèi)定模式的自由度的比率)乘以GFI。 PGFI 應(yīng)該等于或大于0.90,越接近1越好。 (5)PNFI 是簡(jiǎn)效擬合優(yōu)度指數(shù),等于PRATIO乘以 NFI。 PNFI應(yīng)該等于或大于0.90,越接近1越好。 (6)NFI 是規(guī)范擬合指數(shù),變化范圍在0和1間, 1 = 完全擬合。按照約定,NFI 小于0.90 表示需要重新設(shè)置模型。越接近1越好。 (7)TLI 是Tucker-Lewis 系數(shù),也叫做Bentler-Bonett 非規(guī)范擬合指數(shù) (NNFI)。TLI接近1表示擬合良好。 (8)CFI 是比較擬合指數(shù),其值位于0和1之間。CFI 接近1表示擬合非常好,其值大于0.90表示模型可接受,越接近1越好。 6. 模型修改
|
 其中x為潛在自變量,y為潛在因變量
其中x為潛在自變量,y為潛在因變量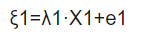

【本文地址】