| Java web中常見編碼亂碼問題(一) | 您所在的位置:網(wǎng)站首頁 › 屬鼠的人為什么不能戴黃金手鐲 › Java web中常見編碼亂碼問題(一) |
Java web中常見編碼亂碼問題(一)
|
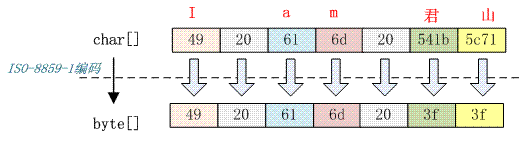
最近在看Java web中中文編碼問題,特此記錄下。 本文將會介紹常見編碼方式和Java web中遇到中文亂碼問題的常見解決方法: 一、常見編碼方式:1、ASCII 碼 眾所周知,這是最簡單的編碼。它總共可以表示128個字符,0~31是控制字符如換行、回車、刪 除等,32~126是打印字符,可以通過鍵盤輸入并且能夠顯示出來的。 2、ISO-8859-1 它是基于ASCII碼基礎(chǔ)上擴展的,它總共能表示256個字符,涵蓋了大多數(shù)西歐語言字符。詳見 ISO-8859-1 編碼?? ?該編碼不支持中文,舉個中文編碼栗子: 字符串“I am 君山”用 ISO-8859-1 編碼,下面是編碼結(jié)果: 由于ISO-8859-1 是單字節(jié)編碼且不支持中文,直接將中文字符轉(zhuǎn)成‘3f’, 3f也就是常見的"?"字符 3、GB2312 它是雙字節(jié)編碼,共包含6763個漢字。 4、GBK 漢字內(nèi)碼擴展規(guī)范,是基于GB2312上拓展的,加入了更多的漢字,能表示21003個漢字。它的編碼 是和GB2312兼容的。也就是說用GB2312編碼的漢字可以用GBK來解碼,并且不會亂碼。倒過來就不完 全可以了,因為GB2312描述的漢字比GBK少。 5、UTF-16 UTF-16是基于Unicode上定義的, 用兩個字節(jié)來表示Unicode的轉(zhuǎn)換格式,它采用定長的表示方法, 即不能什么字符都可以用兩個字節(jié)表示。兩個字節(jié)是16個bit,所以就做UTF-16。(Unicode 囊括了世界 上所有語言,所有語言均可通過Unicode來相互翻譯,詳解?Unicode 編碼) 6、UTF-8 由于UTF-16統(tǒng)一采用兩個字節(jié)來表示一個字符, 有很多字符用一個字節(jié)表示即可。所以存儲空間放 大了一倍,還會增加網(wǎng)絡(luò)傳輸?shù)牧髁?所以推出了UTF-8。 UTF-8采用了一種變長技術(shù),每個編碼區(qū)域有 不同的字碼長度。 通過上面介紹和對比,對于中文字符的處理我想UTF-8是最理想的中文編碼。 二、常見亂碼問題分析1、中文變成看不懂的字符 如果一串中文字符變成了一串看不懂的字符如:"ì ? £ ?? ò ?2?? £ ?",這種情況通常是編碼 字符集與解碼時所用的字符集不一致所造成的。比如使用GBK編碼,如果使用ISO-8859-1解碼 的話結(jié)果就是這樣。 2、一個漢字變成了一個問號 如果編碼和解碼的字符集都是一致的,那么可以確定該字符編碼不支持中文,例如:ISO-8859-1 3、一個漢字變成了兩個問號 中文經(jīng)過多次編碼且其中有一次編碼或者解碼使用了不支持中文的字符集 ? 三、常見案例分析(tomct+google)1、參數(shù)傳輸亂碼 背景:從jsp中傳參數(shù)(包括中文)請求后臺數(shù)據(jù),在后臺獲取到的請求參數(shù)亂碼。 1.1 前端編碼設(shè)置,先講解下jsp中編碼的配置: a、其中contentType中charset用來設(shè)置服務(wù)器發(fā)送給客戶端時的內(nèi)容編碼;pageEncoding 用 來設(shè)置JSP源文件本身和響應(yīng)正文中的字符編碼。通俗的說pageEncoding是jsp文件本身的編碼,如果 pageEncoding設(shè)置為ISO-8859-1,則jsp頁面中不能保存中文字符,會自動提示你是否要設(shè)置為UTF-8. b、jsp文件編碼字符集默認(rèn)為ISO-8859-1, JSP源文件字符集時,優(yōu)先級為pageEncoding> contentType。如果都沒有設(shè)置,默認(rèn)ISO-8859-1。 c、設(shè)置響應(yīng)輸出的字符集時,優(yōu)先級為contentType>pageEncoding。如果都沒有設(shè)置,默認(rèn) ISO-8859-1。 綜上所述,解決該問題亂碼的第一步要設(shè)置jsp中的編碼,最好統(tǒng)一為UTF-8。 exmaple(亂碼示例): 頁面效果如下: ? ? 1.2 后端編碼設(shè)置 a、首先要設(shè)置tomcat編碼,其中要了解兩個參數(shù)(conf/server.xml):URIEncoding 和 useBodyEncodingForURI,可以查看官方文檔說明: http://tomcat.apache.org/tomcat-7.0-doc/config/http.html, 以下是我理解: 1)URIEncoding是對所有GET方式的請求的數(shù)據(jù)進行統(tǒng)一的重新編碼,默認(rèn)編碼為 ?ISO-8859-1(針對URI上的請求參數(shù)) 2)useBodyEncodingForURI:此設(shè)置僅適用于請求的查詢字符串(針對請求體中內(nèi)容)。 ?與URIEncoding不同,它不影響請求URI的路徑部分。如果不知道請求字符編碼(瀏覽器不提供, 并且SetCharacterEncodingFilter不設(shè)置或使用Request.setCharacterEncoding方法的類 似過濾器),默認(rèn)編碼始終為“ISO-8859-1”。URIEncoding設(shè)置對此默認(rèn)值沒有影響。 該參數(shù)為false。通俗的說: true表示get和post的編碼保持一致,post方式的編碼是什么,get方式的編碼就是什么。 false表示get和post的字符編碼各自設(shè)置,互相沒有關(guān)系。 example1(只設(shè)置URIEncoding): ? server.xml controller: @RequestMapping(value = "/testURI", method=RequestMethod.POST) @ResponseBody public String testURI(HttpServletRequest request){ String username = request.getParameter("username"); String nickname = request.getParameter("nickname"); System.out.println("姓名:" + username + ", 昵稱:" + nickname); return "姓名:" + username + ", 性別:" + nickname; }jsp: 輸出結(jié)果: ? ? 姓名:張三, 昵稱:è???? ?? 從結(jié)果中可以看出, URIEncoding只對URI中的參數(shù)進行編碼。 example2:只修改controller中代碼,就都會顯示正常 @RequestMapping(value = "/testURI", method=RequestMethod.POST) @ResponseBody public String testURI(HttpServletRequest request) throws UnsupportedEncodingException{ request.setCharacterEncoding("UTF-8"); String username = request.getParameter("username"); String nickname = request.getParameter("nickname"); System.out.println("姓名:" + username + ", 昵稱:" + nickname); return "姓名:" + username + ", 性別:" + nickname; }其實第二種做法并不是很方便,一般通過設(shè)置URIEncoding+encodingFilter即可解決。 example3(通常做法): web.xml代碼如下,其余跟example1一樣即可。 encodingFilter org.springframework.web.filter.CharacterEncodingFilter encoding UTF-8 forceEncoding true encodingFilter /*? example4: @RequestMapping(value = "/testURI", method=RequestMethod.POST) @ResponseBody public String testURI(HttpServletRequest request) throws UnsupportedEncodingException{ request.setCharacterEncoding("UTF-8"); String username = request.getParameter("username"); String nickname = request.getParameter("nickname"); System.out.println("姓名:" + username + ", 昵稱:" + nickname); return "姓名:" + username + ", 性別:" + nickname; }如果只設(shè)置URIEncoding=ISO-8859-1,request.setCharacterEncoding("UTF-8");只會 對請求體中的參數(shù)進行編碼,所以username是亂碼的。 ? example5: 在example4的基礎(chǔ)上設(shè)置useBodyEncodingForURI="true" 設(shè)置useBodyEncodingForURI=true時,就會將請求參數(shù)和請求體中的參數(shù)根據(jù) request.setCharacterEncoding或者contentType中的字符集編碼。 ? ? 本文先記錄至此,參考文獻有《深入分析Java web解析》《tomcat docs》
? |




【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |