| 知識圖譜推理算法綜述(下):基于語義的匹配模型 | 您所在的位置:網(wǎng)站首頁 › 屬鼠出生在子時的女孩 › 知識圖譜推理算法綜述(下):基于語義的匹配模型 |
知識圖譜推理算法綜述(下):基于語義的匹配模型
|
背景
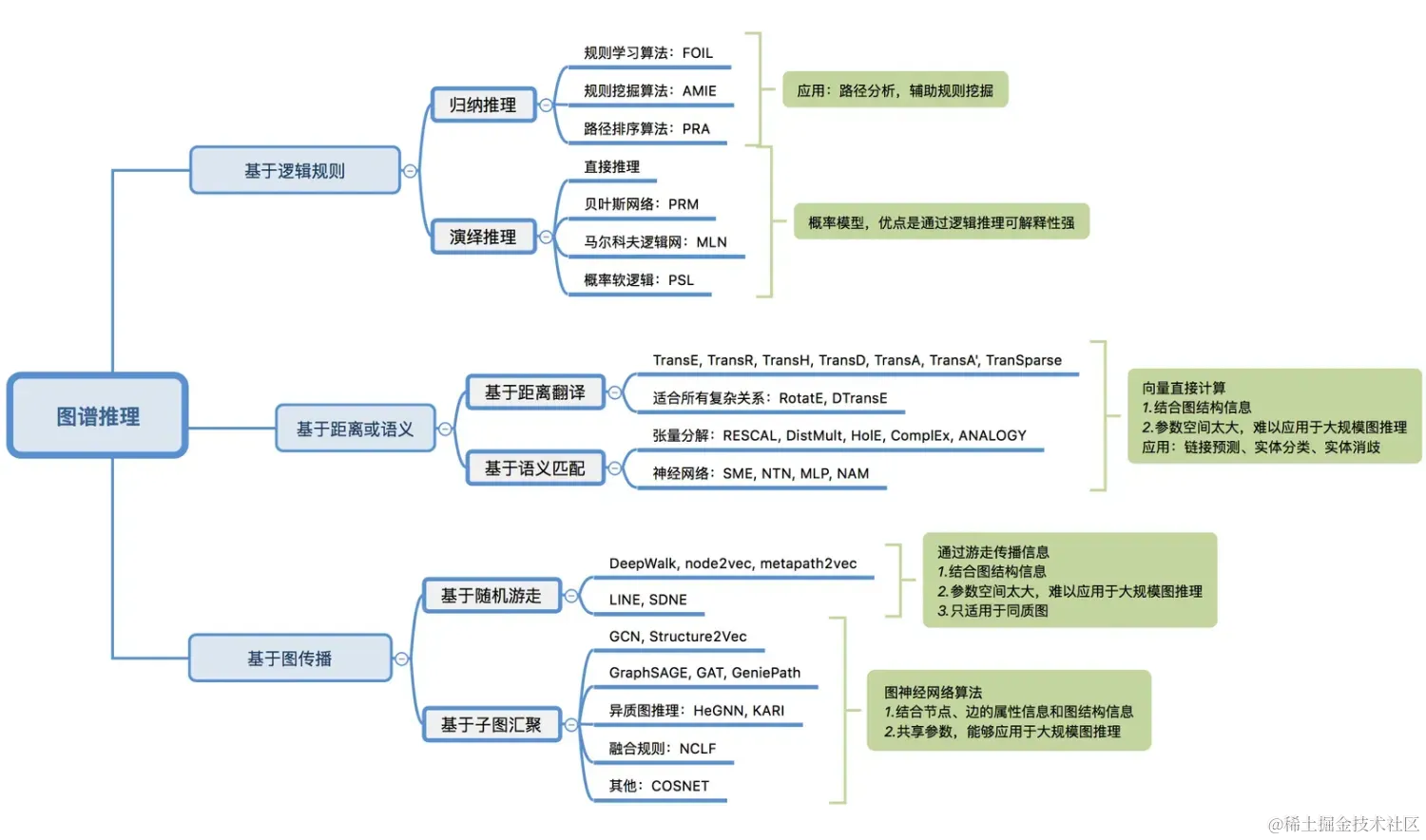
知識圖譜系統(tǒng)的建設需要工程和算法的緊密配合,在工程層面,去年螞蟻集團聯(lián)合 OpenKG 開放知識圖譜社區(qū),共同發(fā)布了工業(yè)級知識圖譜語義標準 OpenSPG 并開源;算法層面,螞蟻從知識融合,知識推理,圖譜應用等維度不斷推進。 OpenSPG GitHub,歡迎大家 Star 關注~:https://github.com/OpenSPG/openspg 本文將梳理知識圖譜常用的推理算法,并討論各個算法之間的差異、聯(lián)系、應用范圍和優(yōu)缺點,為建設知識圖譜的圖譜計算和推理能力理清思路,為希望了解或者工作中需要用到知識圖譜推理算法的同學提供概述和引導。 在知識圖譜推理算法綜述(上):基于距離和圖傳播的模型,我們了解到 “基于距離的翻譯模型”,“基于圖傳播的模型” 的詳細知識圖譜算法梳理。本文為下篇,重點從基于語義的匹配模型:張量分解模型與神經(jīng)網(wǎng)絡類型進行介紹。 知識圖譜算法匯總本章將對常用的圖譜推理算法做一個概括的梳理。業(yè)界算法很多,一篇文章難以做到全面覆蓋,因此我們這里挑選了與圖譜推理強相關的算法進行講解,部分類似的算法挑選了其典型代表進行討論,算法能力范圍盡量覆蓋: 知識融合,包括:實體對齊、屬性融合、關系發(fā)掘、相似性屬性補全;知識推理,包括:鏈接預測、屬性值預測、事件分析、連通性分析、相似性分析。首先,通過一張思維導圖對這些圖推理算法進行匯總:
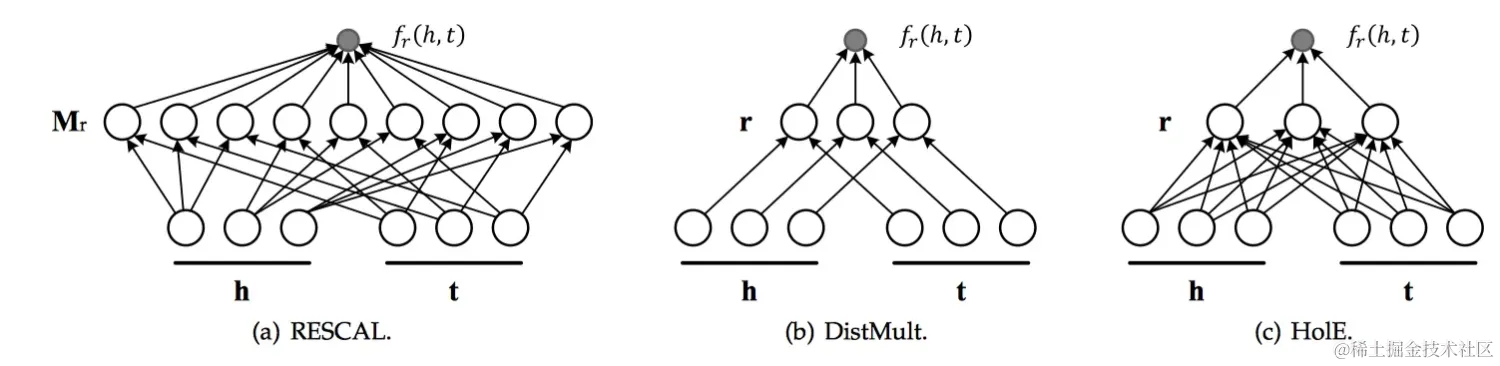
基于規(guī)則的直接推理。只適用于確定性推理,不能進行不確定性推理。比如 marryTo (A,B) -> marryTo (B,A)。 基于貝葉斯網(wǎng)絡的概率關系模型(Probabilistic Relational Models),用條件概率表示因果關系,形成圖結構。 馬爾可夫邏輯網(wǎng) (Markov Logic Network)[4] 是將概率圖模型與一階謂詞邏輯相結合的一種統(tǒng)計關系學習模型,其核心思想是通過為規(guī)則綁定權重的方式將一階謂詞邏輯規(guī)則中的硬性約束進行軟化。即以前的一階謂詞規(guī)則是不能違反的,現(xiàn)在采用了概率來描述。其中,權重反映其約束強度。規(guī)則的權重越大,其約束能力越強,當規(guī)則的權重設置為無窮大時,其退化為硬性規(guī)則。該模型的事實的真值取值 0 或者 1,模型可以學習規(guī)則(結構學習),學習權重,利用規(guī)則和權重推斷未知事實成立的概率。 概率軟邏輯 (Probabilistic Soft Logic)[5]。是馬爾可夫邏輯網(wǎng)的升級版本,最大的不同是事實的真值可以在 [0,1] 區(qū)間任意取值。進一步增強了馬爾可夫邏輯網(wǎng)的不確定性處理能力,能夠同時建模不確定性的規(guī)則和事實。并且連續(xù)真值的引入使得推理從原本的離散優(yōu)化問題簡化為連續(xù)優(yōu)化問題,大大提升了推理效率。因為是連續(xù)值,所以其 “與、或、非” 規(guī)則專門定義了一套公式。 數(shù)值推理:基于圖表示學習(Knowledge Graph Embedding)的推理圖表示學習(Knowledge Graph Embedding)是知識圖譜中的實體和關系通過學習得到一個低維向量,同時保持圖中原有的結構或語義信息。所以一組好的實體向量可以充分、完全地表示實體之間的相互關系,因為絕大部分機器學習算法都可以很方便地處理低維向量輸入,可以應用于鏈接預測、分類任務、屬性值計算、相似度計算等大多數(shù)常見任務。其包含基于距離的翻譯模型,基于圖傳播的模型,基于語義的匹配模型等板塊。本文圍繞基于語義的匹配模型展開討論。 基于語義的匹配模型 這類模型使用基于相似度的評分函數(shù)評估三元組的概率,將實體和關系映射到隱語義空間中進行相似度度量。這類方法分為兩種:一類是簡單匹配模型:RESCAL 張量分解模型及其變種。二類是深度神經(jīng)網(wǎng)絡 SME、NTN(Neural Tensor Networks)神經(jīng)張量模型、MLP、NAM 等等。 算法詳細梳理 基于語義的匹配模型 – 張量分解模型
其目標函數(shù)如下(一種向量內積):
DistMult[15]是為了減少RESCAL的參數(shù)空間,而采用了一個對角矩陣diag?來代替矩陣Mr。這一點與TransH和TransE之間的關系有異曲同工之妙。其目標函數(shù)如下:
需要留意的是,因為采用了對角矩陣diag?,而h、t互換后是相等的,見下式,導致DistMult只能處理對稱關系。比如"A-同學-B",而不能處理非對稱關系,比如"A-父親-B"。
HolE[16]是為了在縮小RESCAL的參數(shù)空間前提下,依然能夠處理非對稱關系而開發(fā)的。方法就是每次先利用快速傅里葉變換對頭向量和尾向量做一個shift i 位,然后再做內積運算。因為頭向量和尾向量shift的位數(shù)不一樣,就打破了對稱性,就可以處理非對稱關系了。其目標函數(shù)如下:
ComplEx[17]和HolE目的相同,為了能夠縮小RESCAL的參數(shù)空間,同時依然能夠處理非對稱關系。ComplEx采用了復數(shù)的方式,擴充到實部和虛部以增加自由度的方式來解決非對稱關系。其目標函數(shù)如下:
ANALOGY[18]融合了DistMult、HolE、ComplEx這三類模型,以期待得到更好的效果。 基于語義的匹配模型–神經(jīng)網(wǎng)絡類型
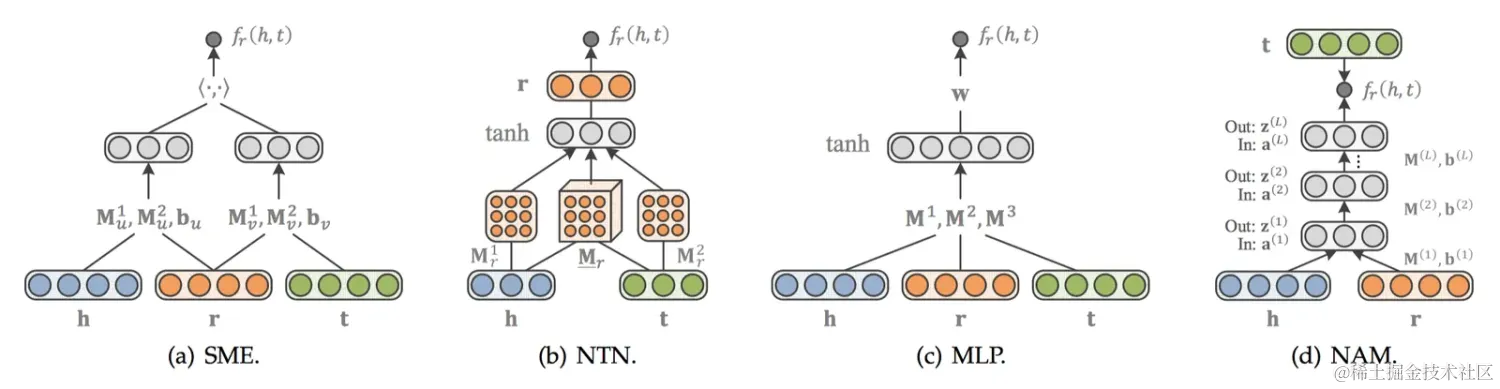
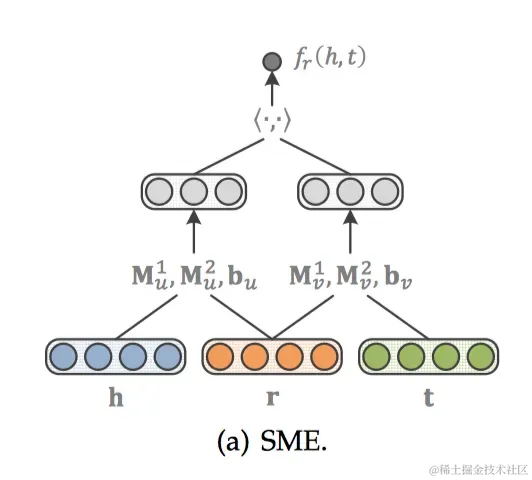
SME[19]利用深度神經(jīng)網(wǎng)絡構造一個二分類模型,將h、r和t輸入到網(wǎng)絡中。先經(jīng)過隱藏層gu和gv分別將h、r以及t、r結合,然后將這兩個結果在輸出層做內積作為得分。如果(h,r,t)在知識圖譜中真實存在,則應該得到接近1的概率,如果不存在,應該得到接近0的概率。得分函數(shù)如下:
隱藏層gu和gv分別將h、r以及t、r結合。有兩個版本,其中一個是線性版本:
另外一個是雙線性版本:
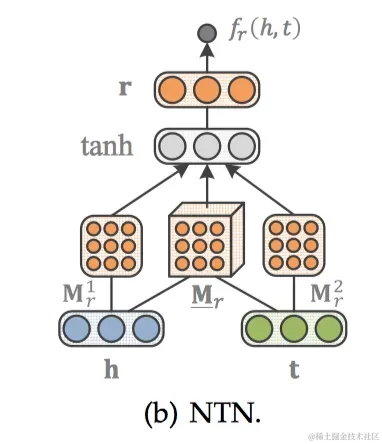
NTN[20]是另外一種神經(jīng)網(wǎng)絡結構。與SME打平的結構不同,NTN先用隱藏層將h、t結合起來,經(jīng)過一個激活函數(shù)tanh以后,在輸出層與關系向量r相結合。得分函數(shù)如下:
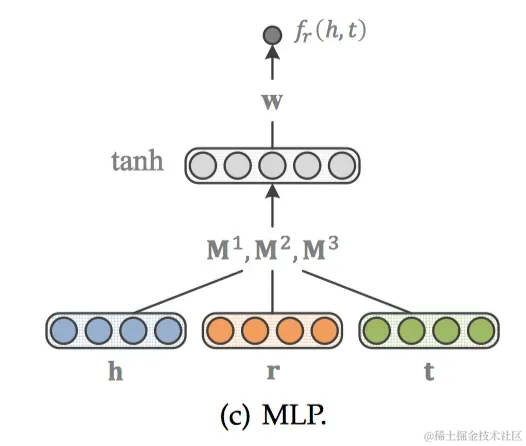
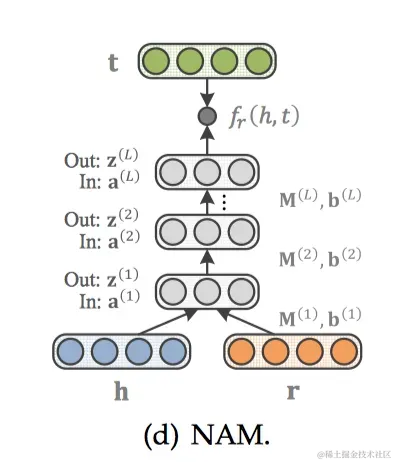
MLP[21]模型更簡單一些,h、r、t經(jīng)過輸入層結合在一起,通過激活函數(shù)tanh后得到非線性的隱藏層,權重為M1、M2、M3,最后再經(jīng)過一個線性的輸出層,權重為w。得分函數(shù)如下:
得分函數(shù)如下:
Logistic loss適合RESCAL系列模型。是基于Close World假設,即將未觀察到的三元組視為不成立。對正確的三元組進行獎勵,對錯誤的三元組進行懲罰。
Pairwise ranking loss更適合Trans系列模型。是基于Open World假設,將未觀察到的三元組視為不一定成立。將事實三元組和未觀測到三元組從距離上盡量分開。
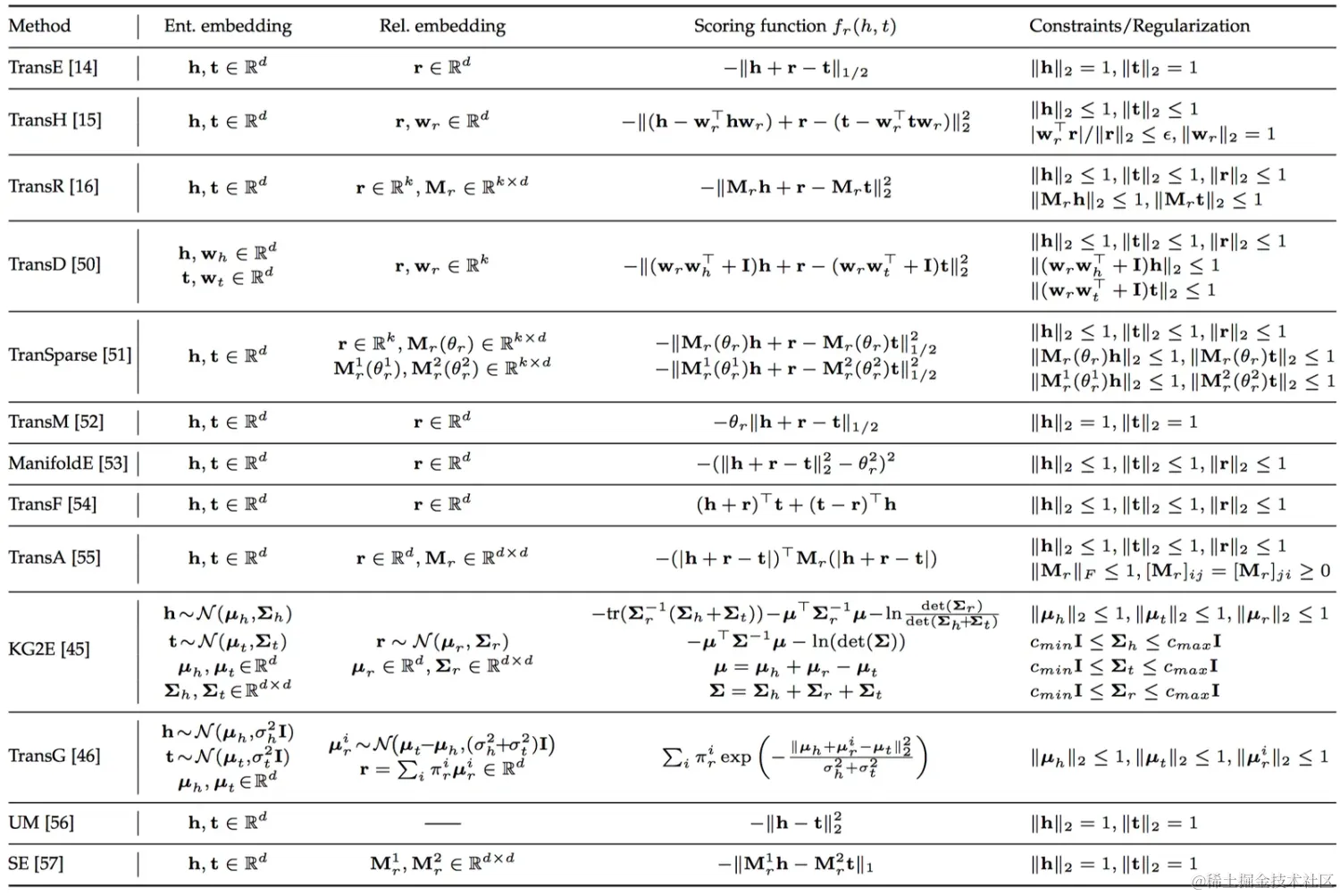
上面這些算法默認都是隨機初始化的。初始化這里也有發(fā)揮的空間,比如可以利用外部知識源做一些預訓練等。 應用 鏈接預測給定三元組(h, r, t)中任意兩個預測第三個。 評估指標有: MR(mean rank)預測排序的平均值MRR(mean reciprocal rank)排序倒數(shù)的平均值Hits@N 排序高于N的百分比AUC-PR 精度-召回曲線下方的面積 三元組分類對給定三元組(h, r, t)判定成立還是不成立。 實體分類這里用了一個技巧,即將實體分類轉化為求 “Is A” 關系。 實體消歧若兩個實體的向量相等,就判定為同一個實體 Trans系列、RESCAL系列、SME系列這三類模型的參數(shù)數(shù)量與節(jié)點數(shù)量成正比,面對大規(guī)模圖譜時往往捉襟見肘。為了克服這個困難,人們引入了圖神經(jīng)網(wǎng)絡模型GNN,圖神經(jīng)網(wǎng)絡后來發(fā)展成為了一個體系,本文后面會介紹到包括GCN、GAT、Structure2vec、GeniePath等等圖神經(jīng)網(wǎng)絡算法。圖神經(jīng)網(wǎng)絡算法通過共享參數(shù)的方式降低了參數(shù)空間,就能適用于大規(guī)模圖推理了。 文獻已經(jīng)下表將上述各類算法做了一個匯總,將上述算法的實體、關系嵌入向量,打分函數(shù),約束信息的表達式做了整理如下:
從算法分類角度 無監(jiān)督: Deepwalk、Node2Vec、Metapath2vec、LINE、Louvain 有監(jiān)督: GCN (半監(jiān)督)、GraphSAGE、SDNE (半監(jiān)督)、GeniePath、GAT、Structure2Vec、HeGNN 從應用角度 鏈接預測: 所有的 embedding 算法都支持鏈接預測。有一個區(qū)別是同質圖模型支持一種關系預測,而異質圖模型支持多種關系預測。(另外加上 ALPS 平臺尚未包括的 trans 系列也可以做鏈接預測)。 實體歸一(相似度計算):所有的 embedding 算法都支持相似度計算。相似度是由具體的任務目標來定義并體現(xiàn)在 loss 中,一般的任務目標有距離相似性(兩個節(jié)點有幾度相連)、結構相似性、節(jié)點類型相似性(label 預測)。 屬性值預測(label 預測):GCN、GraphSAGE、GeniePath、GAT、Structure2Vec、HeGNN 等。 支持異質圖: HeGNN、metaPath2vec、KGNN 支持同質圖: Deepwalk、Node2Vec、LINE、SDNE、GCN、GraphSAGE、GeniePath、GAT、Structure2Vec 關注我們查看官網(wǎng):spg.openkg.cn/ Github:github.com/OpenSPG/ope… SPG 知識圖譜平臺致力于分享 SPG 及 SPG + LLM 雙驅架構及應用相關進展,歡迎大家掃碼關注~
|

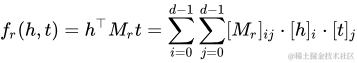
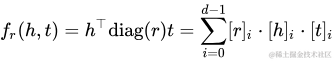
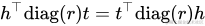
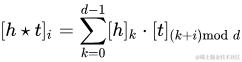
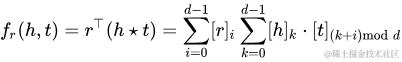
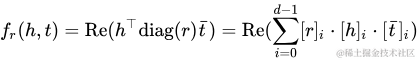
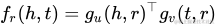
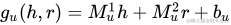
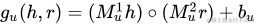
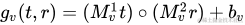
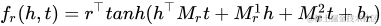
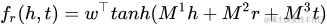

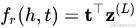
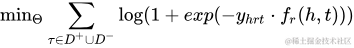



【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |