| 大規(guī)模分布式 AI 模型訓(xùn)練系列 | 您所在的位置:網(wǎng)站首頁 › 屬虎的最佳配偶是哪幾個(gè)屬相 › 大規(guī)模分布式 AI 模型訓(xùn)練系列 |
大規(guī)模分布式 AI 模型訓(xùn)練系列
|
一、背景
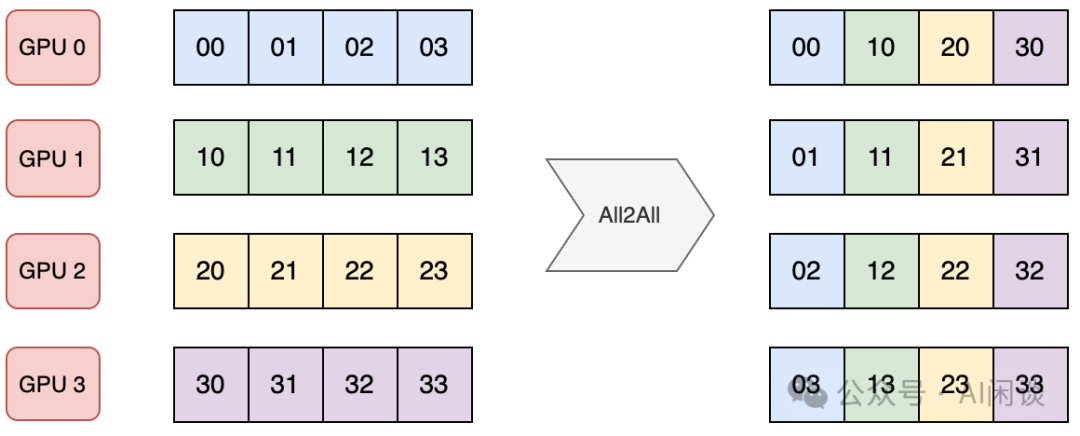
。這篇文章中我們繼續(xù)介紹 MoE 中經(jīng)常使用的專家并行(Expert Parallelism,EP),以及 EP 中涉及的相關(guān) All2All *作和優(yōu)化手段等。 二、引言 2.1 標(biāo)準(zhǔn) All2AllAlltoAll 是集合通信庫(比如 NCCL)中另一種常見的通信原語,用于多個設(shè)備之間進(jìn)行數(shù)據(jù)交換。AlltoAlll *作允許每個參與的設(shè)備將其本地數(shù)據(jù)分發(fā)到其他設(shè)備,同時從其他設(shè)備接收數(shù)據(jù)。 如下圖所示是一種標(biāo)準(zhǔn)的 AlltoAll *作,有 4 個 GPU,每個 GPU 包含 4 個數(shù)據(jù)。通過 AlltoAll *作之后每個設(shè)備都將 4 個數(shù)據(jù)分發(fā)給 4 個 GPU,同時從 4 個 GPU 接收數(shù)據(jù)。可以看出,AlltoAll 很像一個矩陣的轉(zhuǎn)置*作:
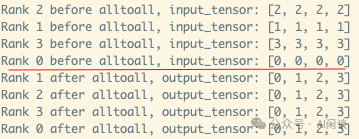
如下圖所示為 Pytorch 實現(xiàn)一個上述標(biāo)準(zhǔn) AlltoAll 的示例:
實際上 NCCL 中并沒有 AlltoAll 通信原語,需要通過 ncclSend 和 ncclRecv 實現(xiàn),其中 ncclSend 和 ncclRecv 是一個 P2P 通信。如下圖所示,每個 Rank 都發(fā)送 nranks 塊數(shù)據(jù),同時接收 nranks 塊數(shù)據(jù)就實現(xiàn)了 AlltoAll 的功能。(可以參考 Point-to-point communication — NCCL 2.22.3 documentation)
類似的方式就可以實現(xiàn) one2all(Scatter)*作:
類似的方式也可以實現(xiàn) all2one(Gather)*作:
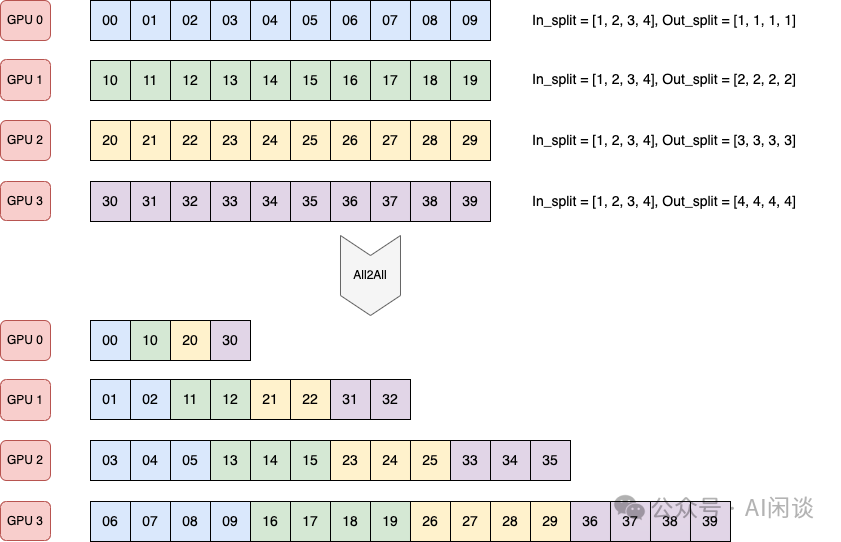
實際上有些場景并非均勻發(fā)送和接收,有可能發(fā)送到不同設(shè)備的數(shù)據(jù)量不同,從不同設(shè)備接收的數(shù)據(jù)量也可能不同。Pytorch 的 “torch.distributed.all_to_all_single” 提供了 input_split_sizes 和 output_split_sizes 參數(shù)來支持: input_split_sizes 表示向每個設(shè)備發(fā)送的數(shù)據(jù)量。 output_split_sizes 表示從每個設(shè)備接收的數(shù)據(jù)量。 如下圖所示,4 個 GPU,每個 GPU 都包含 10 個數(shù)據(jù): 4 個 GPU 都向 GPU k 發(fā)送 k+1 個數(shù)據(jù)(比如,都向 GPU 3 發(fā)送 4 個數(shù)據(jù))。 GPU k 從所有 GPU 都接收 k+1 個數(shù)據(jù)(比如,GPU 2 從所有 GPU 都接收 3 個數(shù)據(jù))。
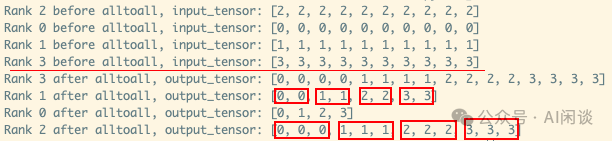
如下圖所示為 Pytorch 實現(xiàn)一個上述非標(biāo)準(zhǔn) all2all 的示例:
PS:需要指出的是,上述接口中 output_split_sizes 和 input_split_sizes 的個別值也可以是 0,表示不從某個設(shè)備接收,或者不向某個設(shè)備發(fā)送數(shù)據(jù)。如上所示,all2all 底層是用 ncclSend 和 ncclRecv 實現(xiàn),很容易可以做到這一點。 2.3 兩次 All2All上述非標(biāo)準(zhǔn) All2All 中有個問題:有些時候當(dāng)前設(shè)備只知道要向其他設(shè)備發(fā)送多少數(shù)據(jù),而并不知道需要從其他設(shè)備接收多少數(shù)據(jù)。這個問題可以通過 2 次 all2all 來解決: 第一次 all2all 交換要傳輸?shù)臄?shù)據(jù)量信息,這是一個標(biāo)準(zhǔn)的 all2all *作,如下圖紅框所示。 第二次 all2all 根據(jù)上述獲取的數(shù)據(jù)量信息來執(zhí)行真正的數(shù)據(jù)傳輸,此時是一個非標(biāo)準(zhǔn) all2all *作。
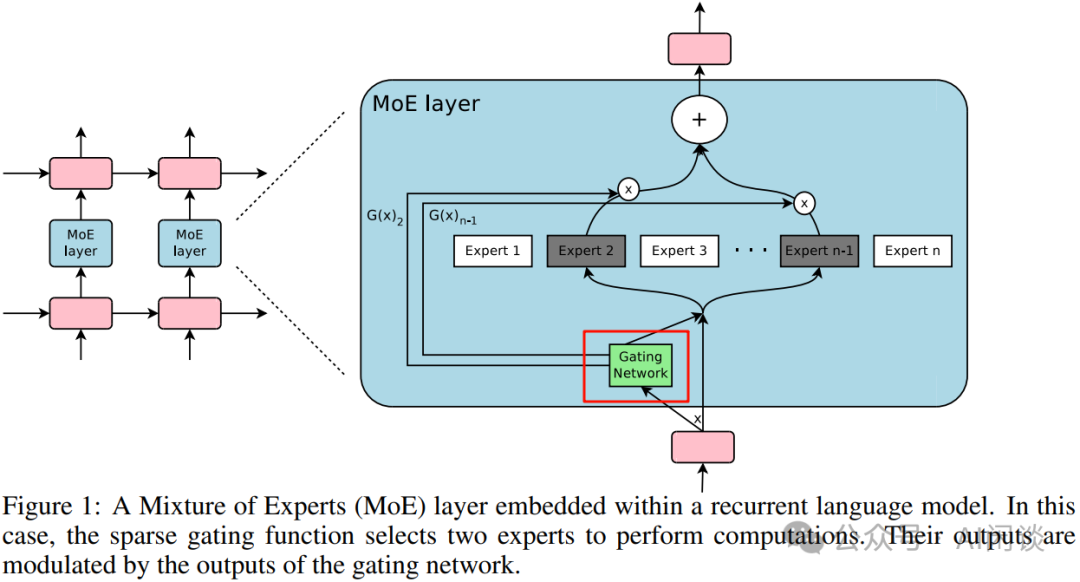
在 [1701.06538] Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer 中,作者(也包括大名鼎鼎的 Geoffrey Hinton 和 Jeff Dean)將 MoE 引入到 LSTM 模型中,并提出了稀疏 MoE(Sparse MoE)的概念。在 Sparse MoE 中可以包含數(shù)千個前饋子網(wǎng)絡(luò),并由可訓(xùn)練的門控網(wǎng)絡(luò)(Gating Network)確定這些專家的稀疏組合。 作者將 MoE 應(yīng)用于語言建模和機器翻譯任務(wù),在相應(yīng)基準(zhǔn)測試中,這些模型可以以較低的計算成本獲得優(yōu)于 SOTA 的效果。 3.2 方案如下圖 Figure 1 所示,作者引入了 Gating Network 機制,該機制可以選出 Topk 的 Expert(Expert 2 和 Expert n-1)進(jìn)行計算。這種稀疏性意味著只有部分專家被激活處理特定的輸入,從而可以大大降低計算量:
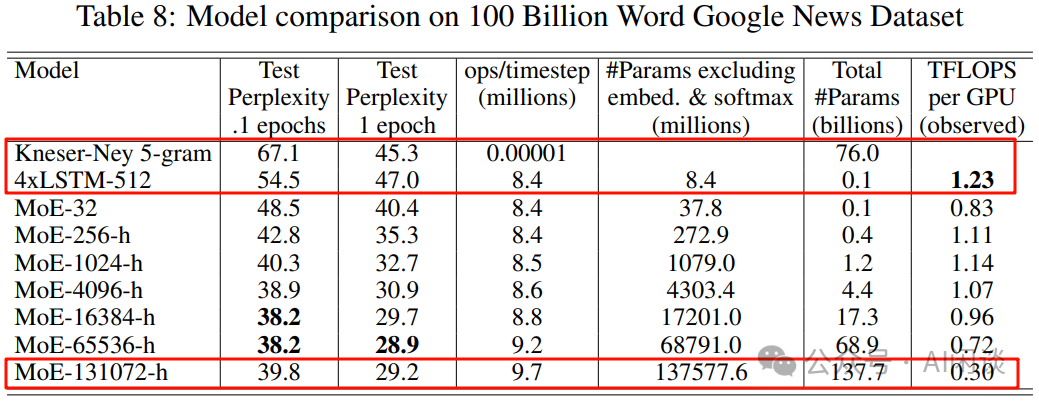
作者也進(jìn)一步證明可以通過靈活控制專家數(shù),來獲得不同容量的模型。如下圖 Table 8 所示,作者分別構(gòu)建了 32/256/1024/4096/16384/65535/131072 個專家的模型,其最大為 137B 的 LSTM 模型。由于稀疏性的存在,雖然 137B 參數(shù)量很大,但可以比當(dāng)時 SOTA 模型更低的計算成本下獲得更好的效果:
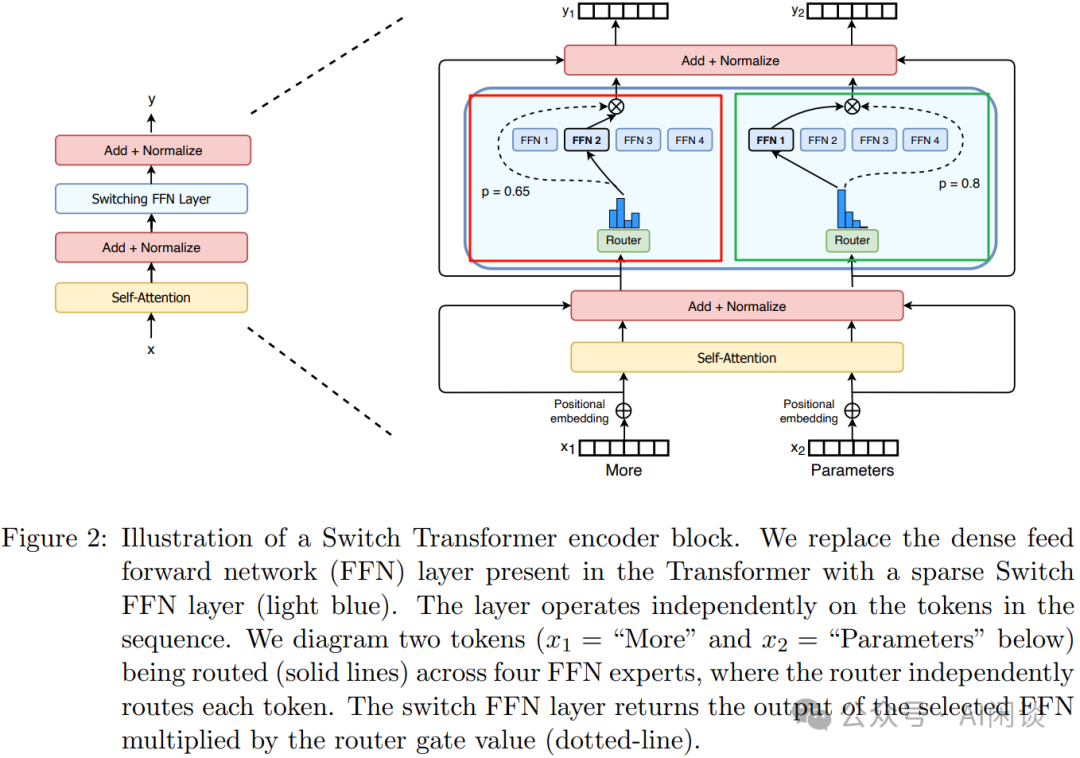
然而,想要高效訓(xùn)練上述的模型卻非常有挑戰(zhàn),假設(shè)有 d 個設(shè)備,采用 Data Parallelism 的 Micro Batch Size 為 b,Total 的 Mini Batch Size 為 d*b。同樣假設(shè)模型中有 n 個 Expert,每個 Sample 都選擇 k 個激活。 基于以上條件,對于每個 DP Worker,每個 Expert 平均有 k*b/n 個 Sample。由于往往 k 遠(yuǎn)小于 n,比如 n 可以是 256/1024/4096/16K/*K/128K,而 k 只是 2 或 4,也就導(dǎo)致 k*b/n 1,在 Gshard 中作者也是使用的 top2 專家。而 Switch Transformer 中,作者發(fā)現(xiàn)僅使用一個專家也能保證模型的質(zhì)量。這樣有 3 個好處: Router 計算更簡單,通信量也更少。 一個 Token 僅對應(yīng)一個專家,計算量也更少。 平均每個專家對應(yīng)的 batch size 至少可以減半。 如下圖 Figure 2 所示,其模型結(jié)構(gòu)和 Gshard 中類似,圖中的紅框和綠框是同樣的 MoE,只是對應(yīng)不同的輸入,經(jīng) Router 后也只連接一個專家:
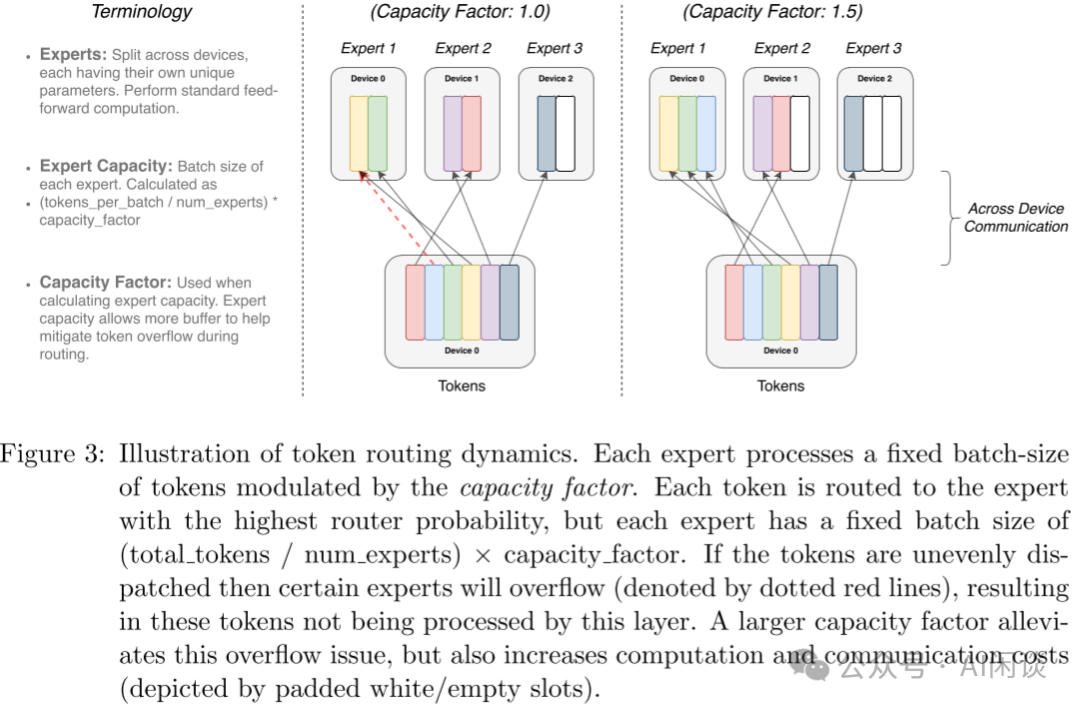
作者采用 Mesh-TensorFlow(PS:之前的文章中介紹過),其提供和 TensorFlow 相似的 API,提供了更簡單的分布式數(shù)據(jù)并行和模型并行。作者的模型主要針對 TPU 設(shè)計,其在模型訓(xùn)練中不支持動態(tài) Tensor shape,也就是要求每個專家輸入的 Tensor shape 是固定的。然而,路由是動態(tài)的,相應(yīng)路由到每個專家的 Tensor 的 shape 也是動態(tài)的,為了解決這一問題,作者使用了專家容量(Expert Capacity),如下所示,專家容量為每個 Batch 中總的 Token 數(shù)除以專家數(shù),然后再乘以容量因子(Capacity Factor),即可得到專家容量(每個專家對應(yīng)的 Token 數(shù))。
如下圖 Figure 3 所示,有 6 個 Token,3 個專家,平均每個專家 2 個 Token: 容量因子為 1.0:如下圖中所示,則對應(yīng)的專家容量為 2: Expert 1 有 3 個 Token,則需要丟棄一個通過殘差連接直接傳到下一層。 Expert 2 有 2 個 Token,正好。 Expert 3 只有 1 個 Token,需要 Padding 1 個空的 Token。 容量因子為 1.5:如下圖右所示,則對應(yīng)的專家容量為 3: Expert 1 有 3 個 Token,正好。 Expert 2 只有 2 個 Token,需要 Padding 1 個空的 Token。 Expert 3 只有 1 個 Token,需要 Padding 2 個空的 Token。
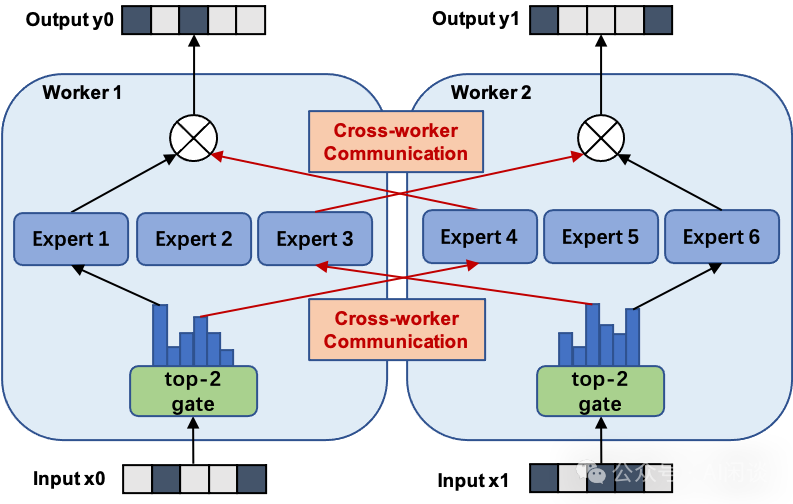
從上也可以看出,容量因子越大,需要 Padding 的 Token 也就越多,無效計算越多;負(fù)載越不均衡,需要 Padding 的 Token 也就越多,無效計算越多。為了更好的負(fù)載均衡,作者同樣添加了 Load Balancing Loss。 六、FastMoE 6.1 摘要之前的高性能分布式 MoE 訓(xùn)練系統(tǒng)主要是針對 Google 的硬件(TPU)和軟件(Mesh TensorFlow),并且不向公眾開放,針對 NVIDIA GPU 和 Pytorch 還沒有相應(yīng)方案。 在 [2103.13262] FastMoE: A Fast Mixture-of-Expert Training System 中,作者提出 FastMoE,其是一個基于 Pytorch 的分布式 MoE 訓(xùn)練系統(tǒng),并提供高度優(yōu)化的高性能加速方案。該系統(tǒng)支持將不同的專家放置在多個節(jié)點上的多個 GPU 中,從而實現(xiàn)專家數(shù)量和 GPU 數(shù)量線性增加。 PS:如下圖所示(來自 fastmoe/doc/readme-cn.md at master),F(xiàn)astMoE 主要針對的是 Expert 比較多的場景,也就是一個 GPU 上有 1 個或多個 Expert。在 2021 年底的 v0.3.0 版本中集成了 Megatron-LM,通過 Megatron-LM 的 Tensor Parallel 來實現(xiàn)一個 Expert 分布在不同的 GPU 上。
FastMoE 的靈活性主要體現(xiàn)在以下幾個方面: 支持任意的網(wǎng)絡(luò)作為專家。作者對專家模塊做了抽象,用戶可以專注設(shè)計專家模塊;此外,F(xiàn)astMoE 也支持將多個專家放在同一個 Worker 上。 針對 Transformer 模型高度優(yōu)化的 FFN。尤其是當(dāng)多個專家放在一個 Worker 時,常見的方式是通過 for 循環(huán)串行的執(zhí)行 Worker 上的多個專家,而作者實現(xiàn)了并行執(zhí)行不同專家的方案。(Batched Gemm) 插件式支持 Pytorch 和 Megatron-LM。作者對 FastMoE 進(jìn)行了必要的抽象,使其很容易與其他框架集成,如下圖所示為與 Megatron-LM 集成的示例:
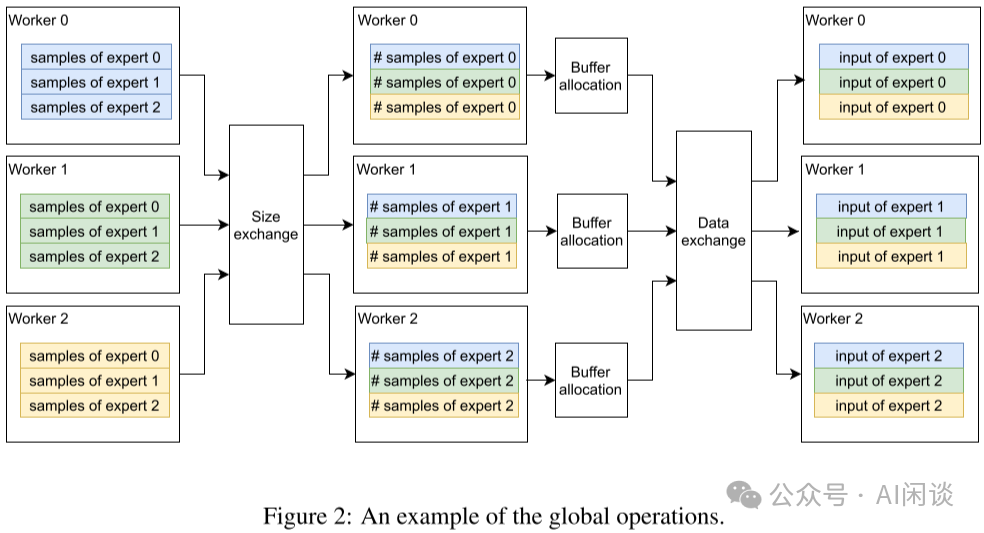
FastMoE 的模型并行方案。FastMoE 支持將專家分布在多個節(jié)點的多個 Worker 上,并且將不同 Worker 之間的數(shù)據(jù)通信隱藏起來,模型開發(fā)人員不用考慮。 此外,在分布式 MoE 系統(tǒng)中的一個主要挑戰(zhàn)為:動態(tài)路由導(dǎo)致分配給不同專家的輸入樣本數(shù)可能存在很大的差異。作者的方案為:在 Worker 之間交換實際的數(shù)據(jù)之前,先在 Worker 之間交換大小信息,Worker 根據(jù)相應(yīng)信息分配 Buffer,然后傳輸真實的數(shù)據(jù)。(PS:這就是 2.3 的兩次 All2All *作)
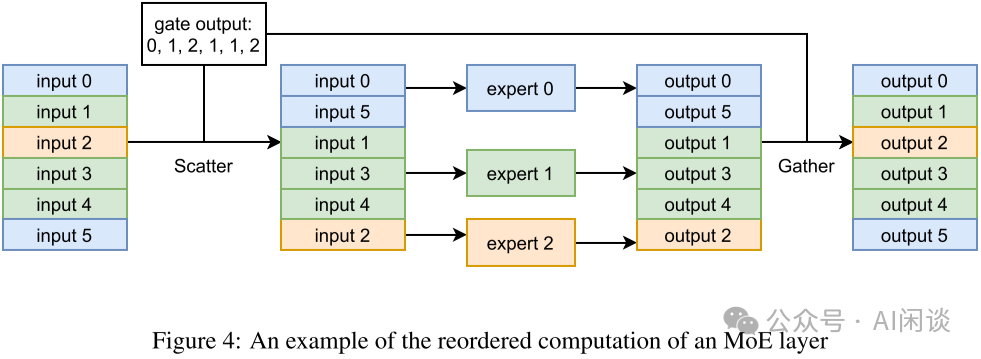
異構(gòu)同步模塊。模型的不同部分可能在不同的 Worker 組間重復(fù),這非常有挑戰(zhàn),因為分布式模塊不得不識別是否需要對參數(shù)的梯度進(jìn)行同步,以及與誰同步。因此,F(xiàn)astMoE 引入了數(shù)據(jù)并行通信組標(biāo)簽: world:需要與所有 Worker 同步。 data parallel:需要與模型并行組正交的數(shù)據(jù)并行組中的 Worker 同步。 none:不需同步。 例如,無論模型并行設(shè)置如何,Gating Network 需要在所有 Worker 之間復(fù)制,因此標(biāo)簽為 world。注意力層可以劃分為模型并行子層,因此其標(biāo)簽為 data parallel。每個 Worker 都包含幾個特定的專家網(wǎng)絡(luò),其標(biāo)簽為 none。 6.3 優(yōu)化激活FastMoE 將所有輸入樣本一起 Batching 后發(fā)給同一個專家。由于數(shù)據(jù)表示的限制,F(xiàn)astMoE 使用專門開發(fā)的 CUDA Kernel 進(jìn)行內(nèi)存移動,以減少開銷。如下圖 Figure 4 所示,給定每個樣本要進(jìn)入的索引(Gating 輸出),通過 Scatter *作(PS:其實也是 All2All,詳情看 6.5)將所有樣本按照對應(yīng)順序進(jìn)行排布,執(zhí)行完專家計算之后,再按照相反的 Gather *作(PS:其實也是 All2All,詳情看 6.5)進(jìn)行復(fù)原。(gate output 應(yīng)該為 0, 1, 2, 1, 1, 0 ?)
如下圖 Figure 8 所示,S 表示 Send,R 表示 Receive,C 表示 Compute,通過利用 CUDA 的 Multi Stream 機制,可以最大限度實現(xiàn)通信和計算的 overlap,實現(xiàn)加速的目的:
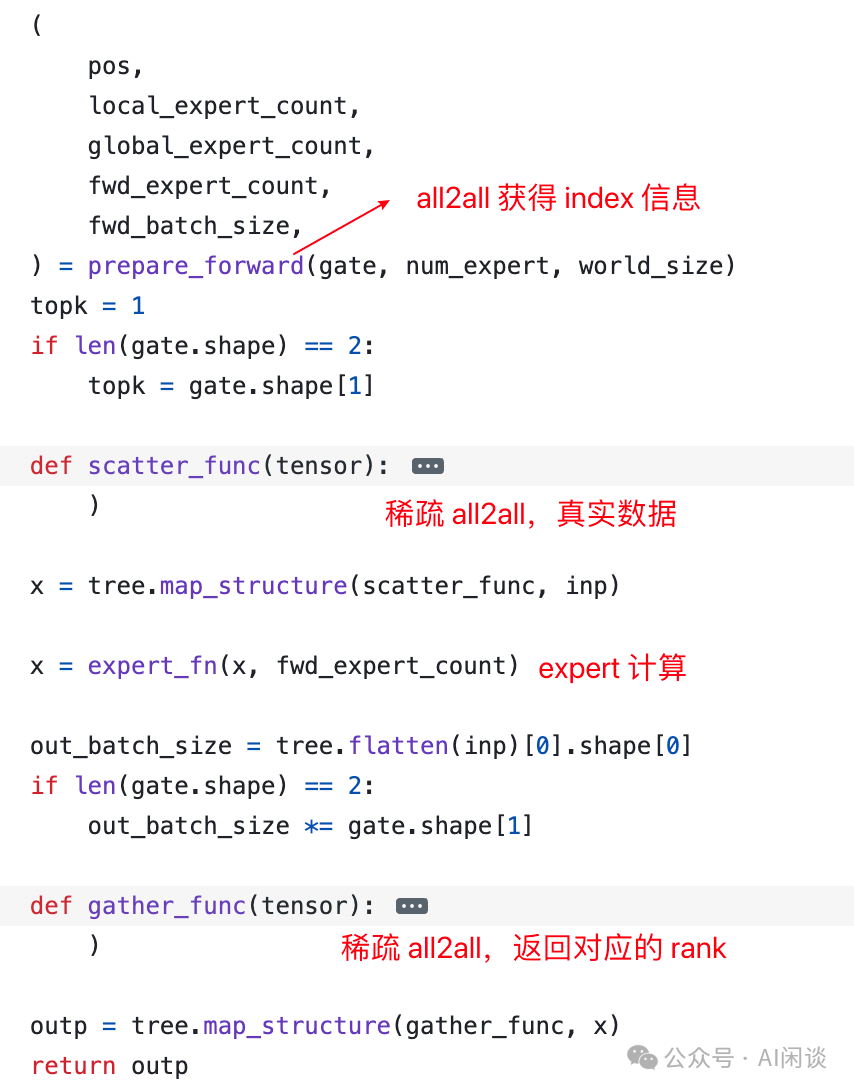
需要說明的是,F(xiàn)astMoE 中并不是直接調(diào)用 Pytorch 的 all2all 來實現(xiàn) Token 的分發(fā)。如下圖所示: prepare_forward():通過 all2all 獲得相應(yīng)的索引、大小信息。(PS:有些實現(xiàn)也會用 AllGather) scatter():稀疏 all2all,分發(fā) Token。 expert_fn():執(zhí)行 Expert 函數(shù)。 gater():稀疏 all2all,Token 重新返回 Rank,此時不需要再額外獲取索引、大小信息。
如下圖所示為 prepare_forward() 的具體實現(xiàn),可以看出其為非稀疏 all2all() *作:
如下圖所示,作者實現(xiàn)了 Global_Scatter 函數(shù),可以理解為一個稀疏的 all2all *作,因為并不是每個 Rank 都會向其他 Rank 分發(fā),也不是每個 Rank 都從所有 Rank 接收。(參考:fastmoe//cuda/global_exchange.h)
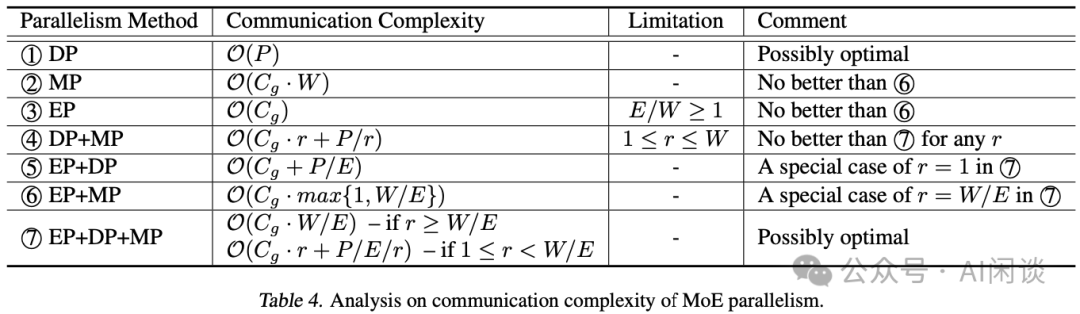
之前的 MoE 分布式訓(xùn)練系統(tǒng)往往采用靜態(tài)執(zhí)行方式(Tensor 的 Shape 在執(zhí)行中不能改變),導(dǎo)致經(jīng) Token 路由之后可能存在 Token 丟棄或者 Padding 無效計算的問題,導(dǎo)致計算效率比較低。 在 [2206.03382] Tutel: Adaptive Mixture-of-Experts at Scale 中,作者提出了 Tutel,其具備動態(tài)自適應(yīng)并行和流水并行(PS:非流水線并行)機制。Tutel 中作者設(shè)計了一個統(tǒng)一布*來分發(fā) MoE 模型參數(shù)和輸入數(shù)據(jù),并利用其實現(xiàn)可切換并行性和動態(tài)流水并行,而無需引入數(shù)學(xué)不等價*作或者 Tensor 遷移開銷,可以在運行時以零成本實現(xiàn)自適應(yīng)并行/流水并行優(yōu)化。基于這一關(guān)鍵設(shè)計,Tutel 實現(xiàn)了各種 MoE 加速技術(shù),包括 Flexible All-to-All、二維分層(2DH)All-to-All,以及快速編碼、解碼等。綜合所有技術(shù),Tutel 相比之前的方案,在 16 個和 2048 個 A100 GPU 上,單個 MoE 層的速度提升 4.96x 和 5.75x。 作者評估表明,Tutel 可以高效地運行 SwinV2-MoE,其基于 Swin Transformer V2 構(gòu)建。使用 Tutel 訓(xùn)練和推理 SwinV2-MoE 比 Fairseq 加速 1.55x 和 2.11x。同時,SwinV2-MoE 在預(yù)訓(xùn)練及下游視覺任務(wù)中比對應(yīng)的密集模型實現(xiàn)了更高的準(zhǔn)確性。 7.2 自適應(yīng) MoE鑒于 EP、DP 和 MP 派生了 7 種不同的并行方法組合,一種方案是為每種方法設(shè)計一個執(zhí)行流程,并使其可與其他方法切換。然而,實際上沒有必要設(shè)計 7 個執(zhí)行流程,因為其可以簡化為更小但效率相當(dāng)?shù)膯栴}。作者的方法是分析所有并行方法的復(fù)雜性,以將它們縮小到最小子集(這里作者只考慮最重要的通信復(fù)雜性,所有 GPU 都執(zhí)行相同的計算,計算復(fù)雜度相同,通信復(fù)雜性直接決定了一種并行方法相比其他方法的效率)。如果它們滿足以下條件則將其刪除: 在任何情況下都不是最佳的。 是另一種方法的特例。 如下圖 Table 3 所示為一些常見的參數(shù):
作者在參數(shù)表里沒有具體介紹 r 參數(shù),只在后文介紹,表示每個專家的 TP 數(shù),也就是每個專家分布在幾個 GPU 上: 如果 r=1,則表示 EP+DP+MP 變?yōu)?EP+DP 如果 r= W/E,則表示 EP+DP+MP 變?yōu)?EP+MP 如下圖 Table 4 所示,經(jīng)過一系列比較,作者得出結(jié)論,該子集只包含 DP(1) 和 EP+DP+MP(7): 對于 DP(1):僅數(shù)據(jù)并行,不過采用的是 ZeRO-DP Stage-3,可以將模型參數(shù)分布在多個 GPU 設(shè)備,在前向計算的時候通過 All-Gather *作獲取所有模型參數(shù)進(jìn)行計算。在反向時,執(zhí)行一次 Reduce-Scatter。 對于 MP(2):僅模型并行,每個 GPU 上都只有模型的 1/W,所有 GPU 加起來有一份完整模型。只要能使用 EP,則總會差于 EP+MP(6)。 對于 EP(3):只有專家數(shù)量 >= GPU 數(shù)量才有意義,因此作者假設(shè)專家數(shù)量 < GPU 數(shù)量,這也是當(dāng)前 LLM-MoE 的現(xiàn)狀,不用考慮純 EP 的方案。
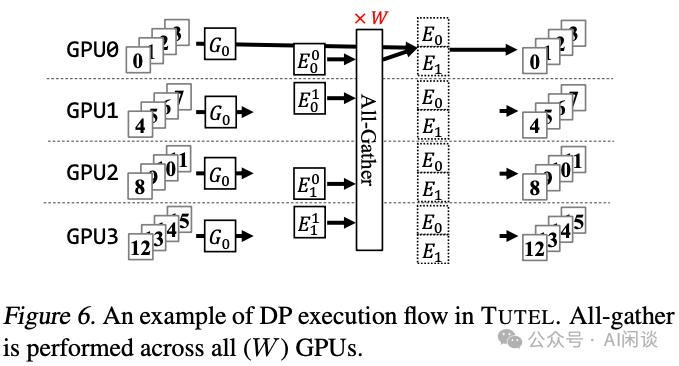
如下圖 Figure 6 所示為相應(yīng)的 Zero-DP,假設(shè)有 4 個 GPU,模型有 2 個專家,則每個 GPU 都只存儲某個專家的 1/2。在前向計算時需要一次 All-Gather 獲取到 2 個完整的專家參數(shù)。
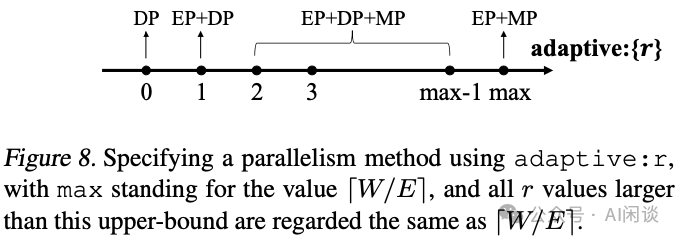
經(jīng)過如上的分析后,作者得出了不同的分布式方案,如下圖 Figure 8 所示,假設(shè) ZeRO-DP 為 r=0,根據(jù) r 的不同值可以選擇不同的策略,特殊情況為上述介紹的 r=1 和 r=W/E:
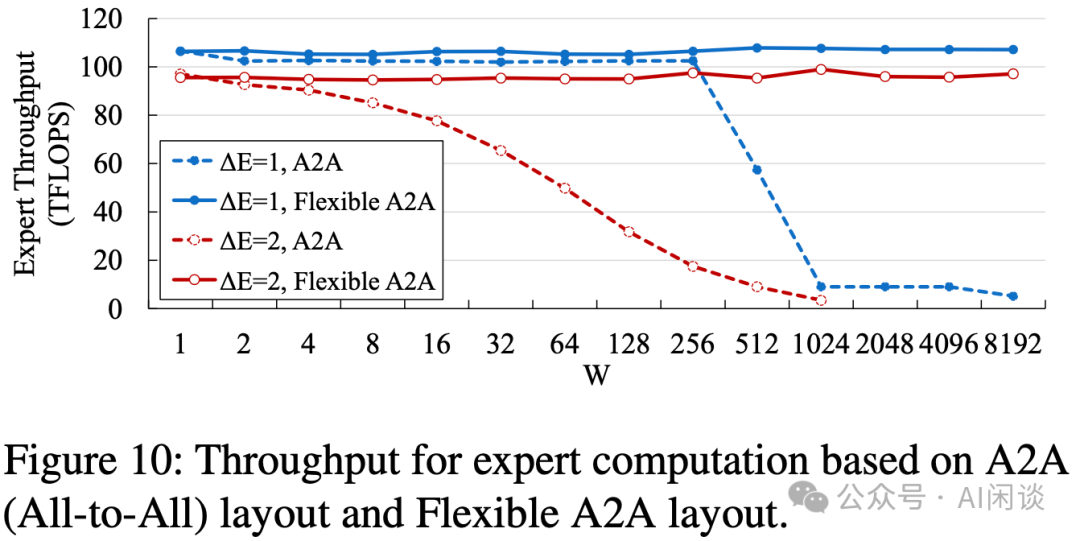
常規(guī)的 FFN 層計算時,All-to-All 的 data layout 會和 Word-Size 有關(guān),當(dāng) Word-Size(GPU)數(shù)目比較大時,性能可能會下降比較多:
PS:出現(xiàn)這一問題的主要原因是:FFN layer 主要為矩陣乘法,GPU 處理大矩陣乘法非常高效,而如果矩陣中的某一維度比較小時,會導(dǎo)致矩陣乘法處于 Roofline-Model 的 Memory-Bound 區(qū)域,導(dǎo)致無法充分發(fā)揮 GPU 算力,并且維度越小此瓶頸越明顯。當(dāng) World-Size 為 256 時,對應(yīng)的矩陣短邊為 16384/256=*,可能正好在 Roofline-Model 的轉(zhuǎn)折點,這也是為什么當(dāng) Worhd-Size 進(jìn)一步增大時性能會進(jìn)一步降低。 Flexible All-to-All 的目的是去除和 World-Size 的相關(guān)性,如下圖為優(yōu)化后的效果:
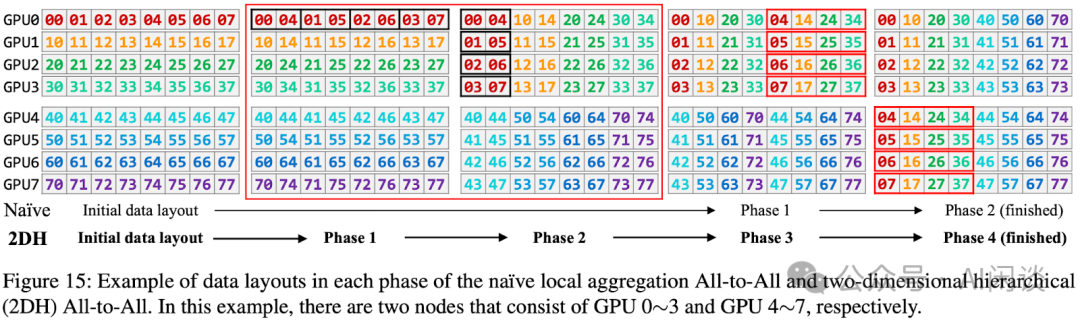
如下圖 Figure 15 所示,2DH All-to-All 的主要思路是充分考慮數(shù)據(jù)的*部性(GPU 內(nèi),同 node GPU、多 node GPU),將非連續(xù)內(nèi)存空間對齊到連續(xù)內(nèi)存空間,并將多個小的通信合并成大的通信: 第一列 -> 第二列:GPU 內(nèi)部交換數(shù)據(jù)(無通信) 第二列 -> 第三列:同 node 的 GPU 間交換數(shù)據(jù)(NVLink) 第三列 -> 第四列:GPU 內(nèi)部交換數(shù)據(jù)(無通信) 第四列 -> 第五列:跨 node 的 GPU 間交換數(shù)據(jù)(網(wǎng)絡(luò))
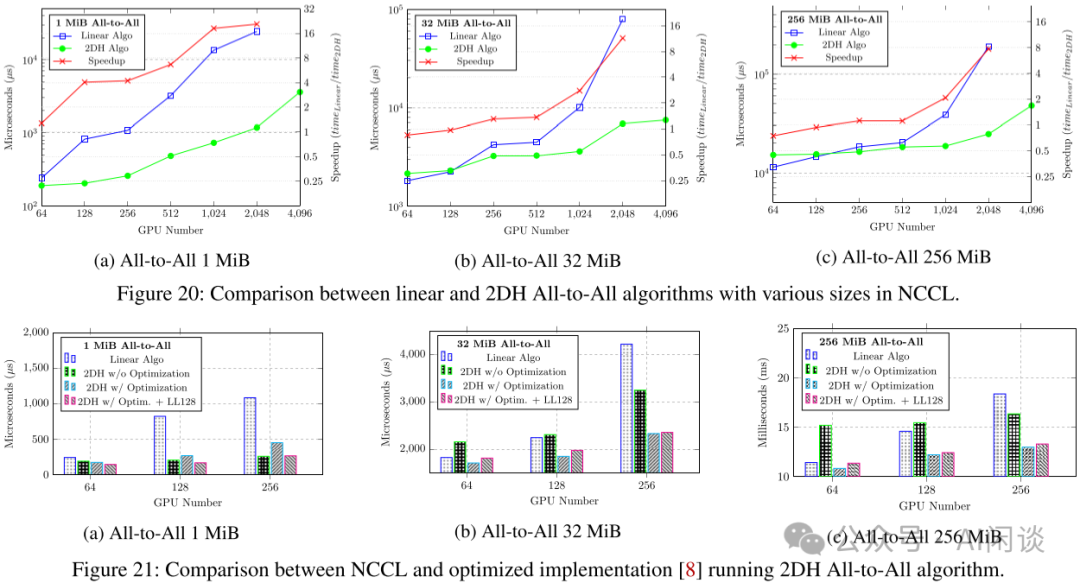
如下圖 Figure 20 和 Figure 21 所示,提出的 2DH All-to-All 比基線提升明顯:
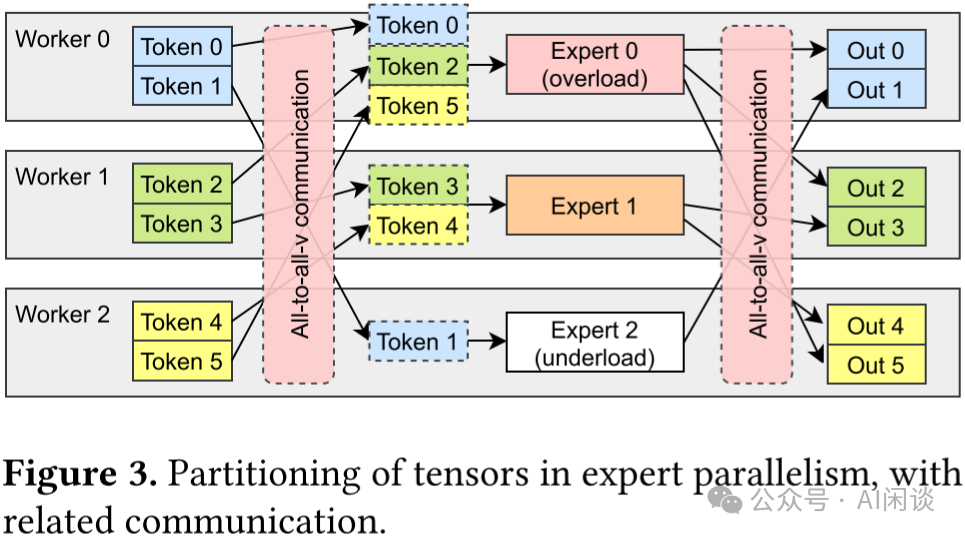
如下圖 Figure 3 所示,在專家并行模式下,專家層的前后會分別引入 All-to-All 通信*作。前一個 All-to-All 用于將每個 Worker 上的 Token 按照 Router 后對應(yīng)的專家發(fā)送到專家所在的 GPU,也叫 All-to-All(Dispatch);而后一個 All-to-All 用于將專家計算后的 Token 重新按照原來的方式排列,也叫 All-to-All(Combine)。
在 All-to-All(Dispatch)*作之前需要準(zhǔn)備好 All-to-All 的輸入,也叫 Encode;在 All-to-All(Combine)*作之后需要解包 All-to-All 的輸出,組織為原始的順序,也叫 Decode。而很多框架中 Encode 和 Decode 的實現(xiàn)都不夠高效,有很多無效計算,因此作者定制了高性能 CUDA Kernel 來優(yōu)化,如下圖(a)為未優(yōu)化的 Encode,(b)為優(yōu)化后的 Encode。
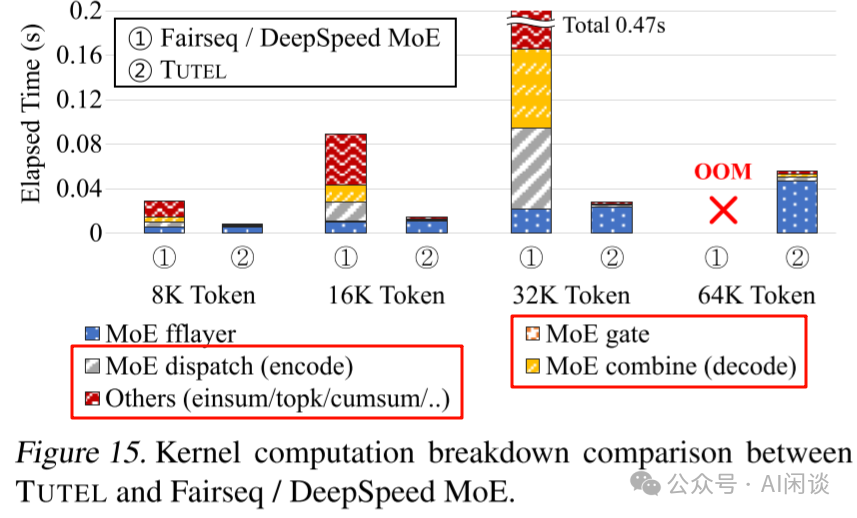
如下圖 Figure 15 所示,優(yōu)化后 Encode、Decode 相關(guān)的時間大幅降低(此外也可以有效節(jié)約顯存):
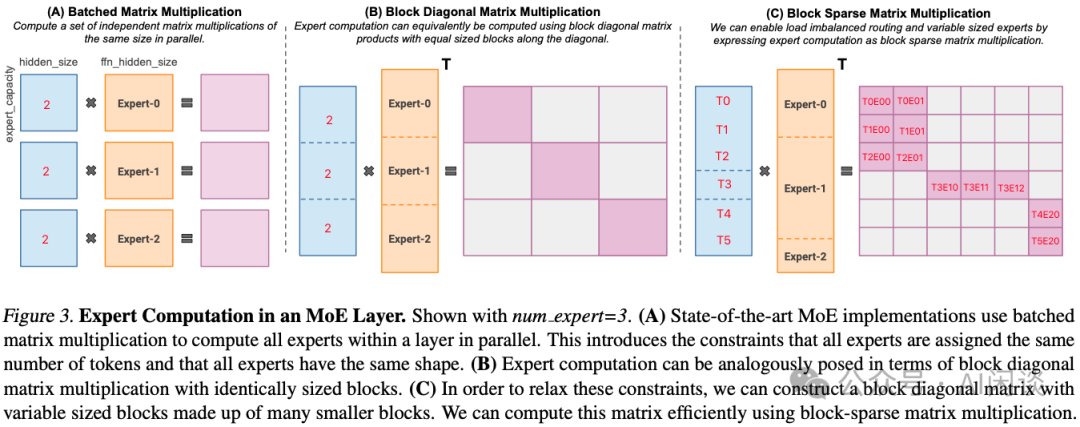
此外,在 Tutel 中,作者也采用了 Multi-Stream 機制來實現(xiàn)計算和通信的重疊,以提升效率,這里不再展開。 八、MegaBlocks 8.1 摘要MegaBlocks([2211.15841] MegaBlocks: Efficient Sparse Training with Mixture-of-Experts) 是斯坦福大學(xué)、微軟及谷歌聯(lián)合發(fā)布的在 GPU 上高效訓(xùn)練 MoE 的系統(tǒng)。之前我們提到過,MoE 的 Router 負(fù)載不均衡會導(dǎo)致需要刪除 Token 或者 Padding 填充,本文中作者采用塊稀疏*作對 MoE 計算進(jìn)行了重新調(diào)整,并開發(fā)了新的塊稀疏 GPU Kernel,以高效處理 MoE 中存在的動態(tài)性。作者提出的方法中從不丟棄 Token,并能與現(xiàn)有硬件很好的結(jié)合。 與最先進(jìn)的 Tutel 庫相比,端到端訓(xùn)練速度提高 40%;與使用高度優(yōu)化的 Megatron-LM 框架訓(xùn)練的 DNN 相比,端到端訓(xùn)練速度提高 2.4x。 PS:需要說明的是,MegaBlocks 主要針對的還是單個 GPU 上包含多個專家的場景。 8.2 方法MegaBlocks 主要解決的是 1 個 GPU 上有多個專家時,由于負(fù)載不均衡導(dǎo)致的 Token 丟棄或者 Padding 無效計算問題。如下圖 Figure 3 所示,假設(shè)有 3 個專家,每個專家的 Capability 為 2 個 Token,Router 后分配給 3 個專家的 Token 分別為 3,1,2,因此 Expert-0 需要丟棄一個 Token,Expert-1 需要 Padding 一個 Token。假設(shè) Token Embedding 維度為 1024,F(xiàn)FN 第一個 MLP 升維后為 4096: (A):對應(yīng) 3 個 (2, 1024) 和 (1024, 4096) 的矩陣乘法,每個輸出都是 (2, 4096) (B):可以表示為 Batch Gemm 來計算,輸出為 (6, 12288),但只有對角線上有 3 個 (2, 4096) 的子矩陣,其他位置為 0。采用稀疏計算不會增加額外的計算量。 (C):同樣可以表示為 Batch Gemm(可變 Shape),但是不丟棄 Token,也不 Padding,相當(dāng)于 (3, 1024),(1, 1024) 和 (2, 1024) 的 3 個矩陣分別不同的 (1024, 4096) 的矩陣相乘,稀疏表示后生成的還是 (6, 12288) 矩陣。PS:這個圖很容易讓人迷惑,圖中的列分塊是作者想要支持可變大小的專家,但并沒有實現(xiàn)。實際上當(dāng)前用的專家大小都相同,所以各個專家列分塊的大小也應(yīng)該相同。
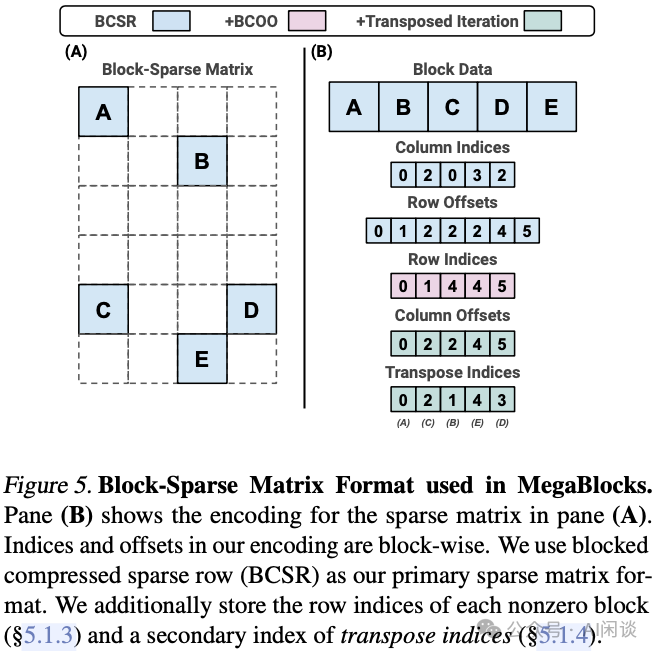
如下圖 Figure 5 所示為對應(yīng)的稀疏分塊矩陣表示方式:
由于新崗位的生產(chǎn)效率,要優(yōu)于被取代崗位的生產(chǎn)效率,所以實際上整個社會的生產(chǎn)效率是提升的。 但是具體到個人,只能說是: “最先掌握AI的人,將會比較晚掌握AI的人有競爭優(yōu)勢”。 這句話,放在計算機、互聯(lián)網(wǎng)、移動互聯(lián)網(wǎng)的開*時期,都是一樣的道理。 我在一線互聯(lián)網(wǎng)企業(yè)工作十余年里,指導(dǎo)過不少同行后輩。幫助很多人得到了學(xué)習(xí)和成長。 我意識到有很多經(jīng)驗和知識值得分享給大家,也可以通過我們的能力和經(jīng)驗解答大家在人工智能學(xué)習(xí)中的很多困惑,所以在工作繁忙的情況下還是堅持各種整理和分享。但苦于知識傳播途徑有限,很多互聯(lián)網(wǎng)行業(yè)朋友無法獲得正確的資料得到學(xué)習(xí)提升,故此將并將重要的AI大模型資料包括AI大模型入門學(xué)習(xí)思維導(dǎo)圖、精品AI大模型學(xué)習(xí)書籍手冊、視頻教程、實戰(zhàn)學(xué)習(xí)等錄播視頻免費分享出來。
該階段讓大家對大模型 AI有一個最前沿的認(rèn)識,對大模型 AI 的理解超過 95% 的人,可以在相關(guān)討論時發(fā)表高級、不跟風(fēng)、又接地氣的見解,別人只會和 AI 聊天,而你能* AI,并能用代碼將大模型和業(yè)務(wù)銜接。 大模型 AI 能干什么?大模型是怎樣獲得「智能」的?用好 AI 的核心心法大模型應(yīng)用業(yè)務(wù)架構(gòu)大模型應(yīng)用技術(shù)架構(gòu)代碼示例:向 GPT-3.5 灌入新知識提示工程的意義和核心思想Prompt 典型構(gòu)成指令調(diào)優(yōu)方法論思維鏈和思維樹Prompt 攻擊和防范… 第二階段(30天):高階應(yīng)用該階段我們正式進(jìn)入大模型 AI 進(jìn)階實戰(zhàn)學(xué)習(xí),學(xué)會構(gòu)造私有知識庫,擴展 AI 的能力。快速開發(fā)一個完整的基于 agent 對話機器人。掌握功能最強的大模型開發(fā)框架,抓住最新的技術(shù)進(jìn)展,適合 Python 和 J*aScript 程序員。 為什么要做 RAG搭建一個簡單的 ChatPDF檢索的基礎(chǔ)概念什么是向量表示(Embeddings)向量數(shù)據(jù)庫與向量檢索基于向量檢索的 RAG搭建 RAG 系統(tǒng)的擴展知識混合檢索與 RAG-Fusion 簡介向量模型本地部署… 第三階段(30天):模型訓(xùn)練恭喜你,如果學(xué)到這里,你基本可以找到一份大模型 AI相關(guān)的工作,自己也能訓(xùn)練 GPT 了!通過微調(diào),訓(xùn)練自己的垂直大模型,能獨立訓(xùn)練開源多模態(tài)大模型,掌握更多技術(shù)方案。 到此為止,大概2個月的時間。你已經(jīng)成為了一名“AI小子”。那么你還想往下探索嗎? 為什么要做 RAG什么是模型什么是模型訓(xùn)練求解器 & 損失函數(shù)簡介小實驗2:手寫一個簡單的神經(jīng)網(wǎng)絡(luò)并訓(xùn)練它什么是訓(xùn)練/預(yù)訓(xùn)練/微調(diào)/輕量化微調(diào)Transformer結(jié)構(gòu)簡介輕量化微調(diào)實驗數(shù)據(jù)集的構(gòu)建… 第四階段(20天):商業(yè)閉環(huán)對全球大模型從性能、吞吐量、成本等方面有一定的認(rèn)知,可以在云端和本地等多種環(huán)境下部署大模型,找到適合自己的項目/創(chuàng)業(yè)方向,做一名被 AI 武裝的產(chǎn)品經(jīng)理。 硬件選型帶你了解全球大模型使用國產(chǎn)大模型服務(wù)搭建 OpenAI 代理熱身:基于阿里云 PAI 部署 Stable Diffusion在本地計算機運行大模型大模型的私有化部署基于 vLLM 部署大模型案例:如何優(yōu)雅地在阿里云私有部署開源大模型部署一套開源 LLM 項目內(nèi)容安全互聯(lián)網(wǎng)信息服務(wù)算法備案…學(xué)習(xí)是一個過程,只要學(xué)習(xí)就會有挑戰(zhàn)。天道酬勤,你越努力,就會成為越優(yōu)秀的自己。 如果你能在15天內(nèi)完成所有的任務(wù),那你堪稱天才。然而,如果你能完成 60-70% 的內(nèi)容,你就已經(jīng)開始具備成為一名大模型 AI 的正確特征了。 這份完整版的大模型 AI 學(xué)習(xí)資料已經(jīng)上傳CSDN,朋友們?nèi)绻枰梢晕⑿艗呙柘路紺SDN官方認(rèn)證二維碼免費領(lǐng)取【保證100%免費】
|








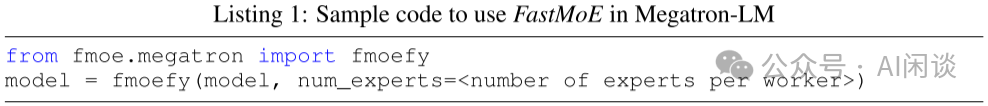








【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |