| 基于Spark的NBA球員數(shù)據(jù)分析 | 您所在的位置:網(wǎng)站首頁 › 屬虎的和屬虎的婚配合適嗎 › 基于Spark的NBA球員數(shù)據(jù)分析 |
基于Spark的NBA球員數(shù)據(jù)分析

【版權(quán)聲明】版權(quán)所有,嚴禁轉(zhuǎn)載,嚴禁用于商業(yè)用途,侵權(quán)必究。 作者:廈門大學信息學院人工智能系2021級研究生 夏佳爾 指導老師:廈門大學數(shù)據(jù)庫實驗室 林子雨 博士/副教授 相關(guān)教材:林子雨、鄭海山、賴永炫編著《Spark編程基礎(chǔ)(Scala版)》 【查看基于Scala語言的Spark數(shù)據(jù)分析案例集錦】 本案例針對NBA球員數(shù)據(jù)進行分析,采用Scala為編程語言,采用Hadoop存儲數(shù)據(jù),采用Spark對數(shù)據(jù)進行處理分析,并對結(jié)果進行數(shù)據(jù)可視化。 一、實驗環(huán)境1)Linux: Ubuntu18.04.6 LTS 2)Hadoop: 3.1.3 3)Spark:3.2.0 4)Python3.8.10 5)Scala:2.12.15 6)IntelliJ IDEA:2022.1 7)sbt:1.6.2 二、數(shù)據(jù)處理 (1)數(shù)據(jù)集說明本次實驗所用數(shù)據(jù)集來自NBA官網(wǎng)所公布的數(shù)據(jù)庫(https://www.nba.com/stats/), 數(shù)據(jù)集爬取了自1970年至2015年共計46年的球員比賽數(shù)據(jù)。可以從百度網(wǎng)盤下載數(shù)據(jù)集(提取碼:ziyu)。數(shù)據(jù)內(nèi)容及字段說明如下: Rk:每個文件中的行號 Player:球員姓名 Pos:球員位置 Age:球員年齡 Tm:所在球隊(Team) G:出場次數(shù)(games) GS:首發(fā)次數(shù)(games started) MP:平均每場出場時間(minutes played) FG:命中次數(shù)(field goals) FGA:投籃出手次數(shù)(field goals attempt) FG%:投籃命中率(field goal percentage) 3P:3分球命中次數(shù)(3-pointers) 3PA:3分球出手次數(shù)(3-pointer attempt) 3P%:3分球命中率(3-pointer percentage) 2P:2分球命中次數(shù) 2PA:2分球出手次數(shù) 2P%:2分球命中率 eFG%:有效投籃命中率(不包含罰籃) FT:罰球(free throw)命中次數(shù) FTA:罰球出手次數(shù) FT%:罰球命中率 ORB:前場籃板(offensive rebound)次數(shù) DRB:后場籃板(deffensive rebound)次數(shù) TRB:籃板總數(shù)(total rebound) AST:助攻次數(shù)(assists) STL:搶斷(steal)次數(shù) BLK:蓋帽(block)次數(shù) TOV:失誤(Turnover)次數(shù) PF:個人犯規(guī)(personal foul)次數(shù) PTS:總得分(points)
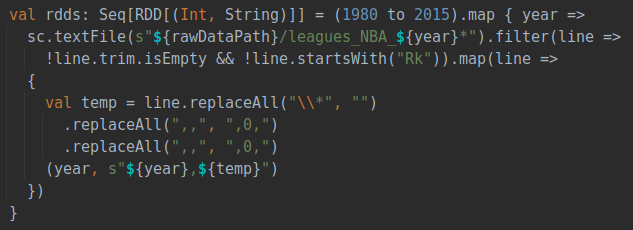
在獲得原始數(shù)據(jù)之后首先通過Hadoop中的HDFS組件將數(shù)據(jù)集存放在分布式文件系統(tǒng)HDFS中。具體步驟如下: ①在終端中啟動HDFS :/usr/local/hadoop/sbin/start-dfs.sh ②在HDFS中創(chuàng)建存放路徑:hdfs dfs -mkdir -p /xje/hadoop/nba ③上傳文件至HDFS:hdfs dfs -put basketball /xje/hadoop/nba 注意:本次實驗所用數(shù)據(jù)集是包含了46個csv文件的文件夾,所以直接上傳了basketball文件夾,使用單文件數(shù)據(jù)集時可直接上傳csv文件。 (3)數(shù)據(jù)集預處理在數(shù)據(jù)分析之前首先對數(shù)據(jù)進行預處理,去除數(shù)據(jù)中的無效數(shù)據(jù)(如空白行)并對數(shù)據(jù)進行規(guī)范化,使得之后的數(shù)據(jù)處理能夠更加順利的進行。
具體作為,直接運行Player_Stats_Preprocess.scala文件,但請確保代碼中rawDataPath是正確的數(shù)據(jù)集路徑。 在清理數(shù)據(jù)集后,由于爬取的數(shù)據(jù)集是按照年份單獨爬取的,所以需要對46個不同年份的數(shù)據(jù)進行整合處理,直接運行ZscoreCalculator.scala文件,代碼會讀取每一年的csv文件進行合并,并且對各項數(shù)據(jù)進行預處理,同時根據(jù)球員每年的各項數(shù)據(jù)計算球員在每一年的zScore,作為對球員表現(xiàn)的評價指標(在實驗流程中詳細說明),最終整合保存為一個包含每一年數(shù)據(jù)的文件。
①首先新建一個工程,點擊File -> New -> Project
②基于SBT構(gòu)建Scala項目,注意選擇Scala版本為2.12.15
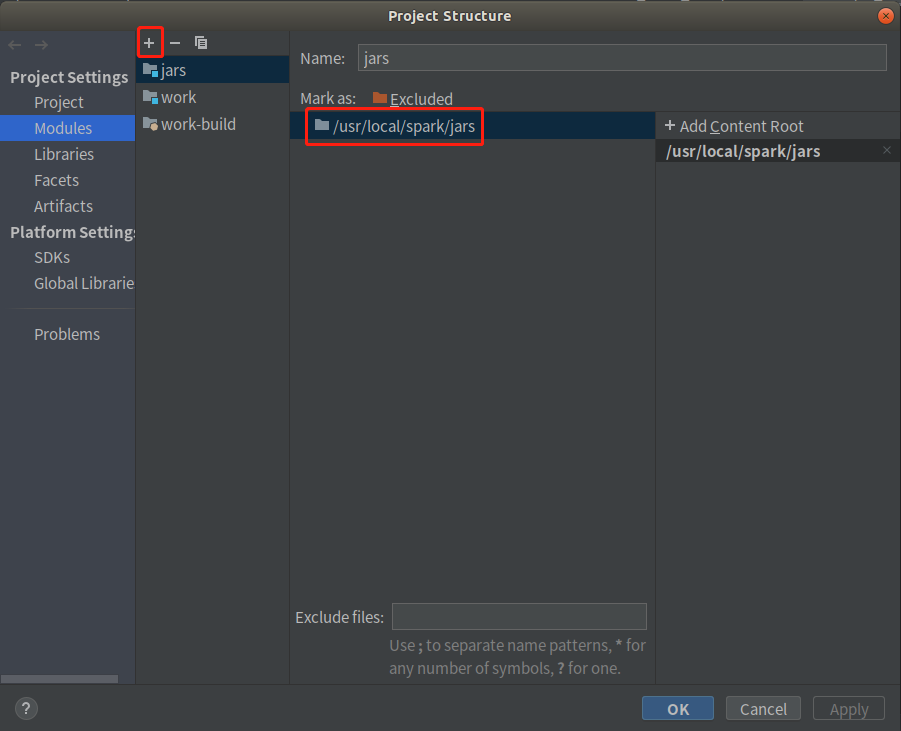
①打開File -> Projects Structure
②添加Spark jar
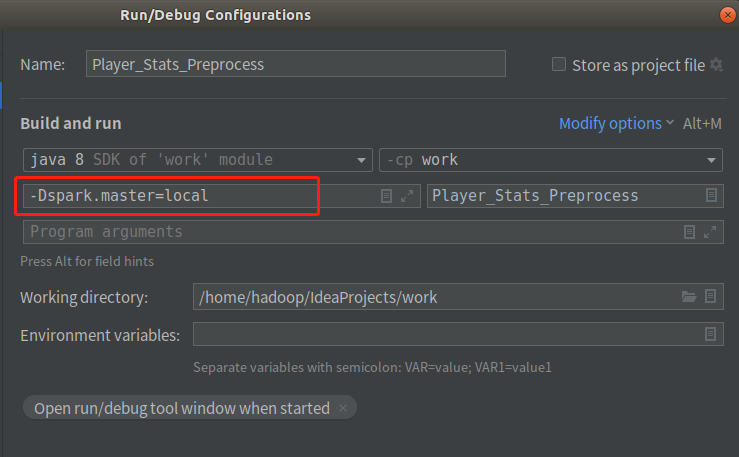
①在右上角選擇Edit Configuration
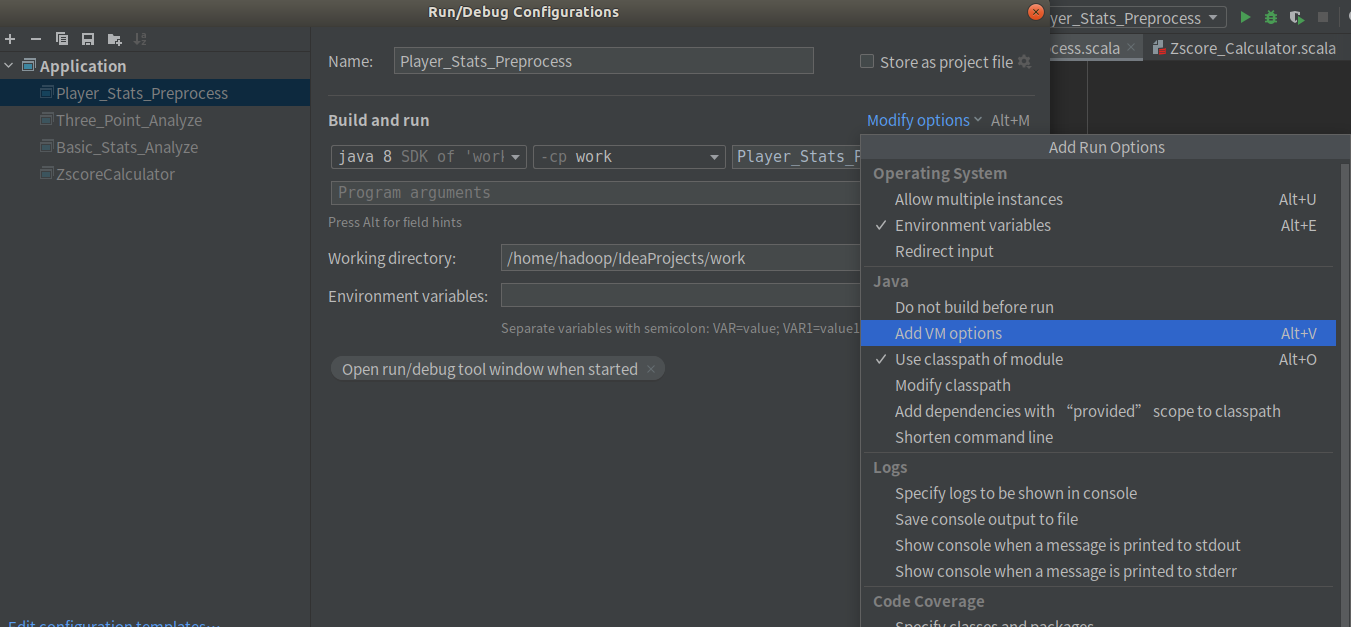
②在Modify option中選擇 AddVM options
③在VM option中輸入-Dspark.master=local指示本程序本地單線程運行
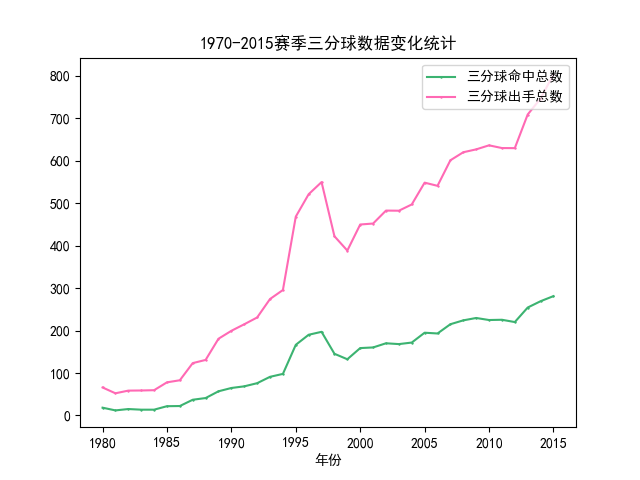
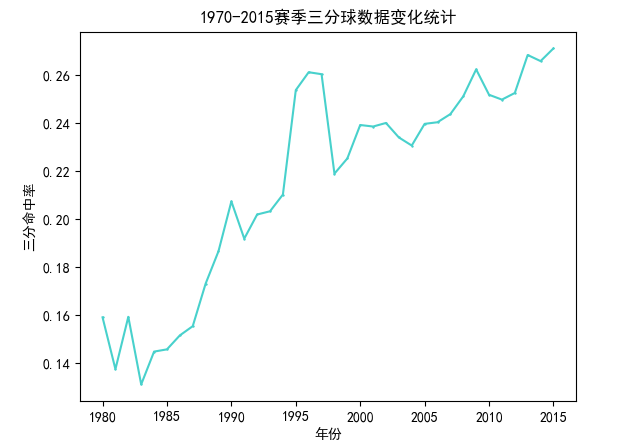
該部分分析隨著賽季發(fā)展,三分球在比賽中的占比變化,主要分析三分球的出手數(shù)、命中數(shù)和命中率。分析前首先聲明一個三分球類來接受所需的三分球相關(guān)的字段數(shù)據(jù),然后分析的具體流程如下: ①讀取csv數(shù)據(jù)集并通過出場數(shù)進行數(shù)據(jù)過濾 ②選擇所需的字段并創(chuàng)建Dataset ③按年進行分組并聚合每一年的三分數(shù)據(jù) ④保存處理完的數(shù)據(jù) 具體代碼如下:
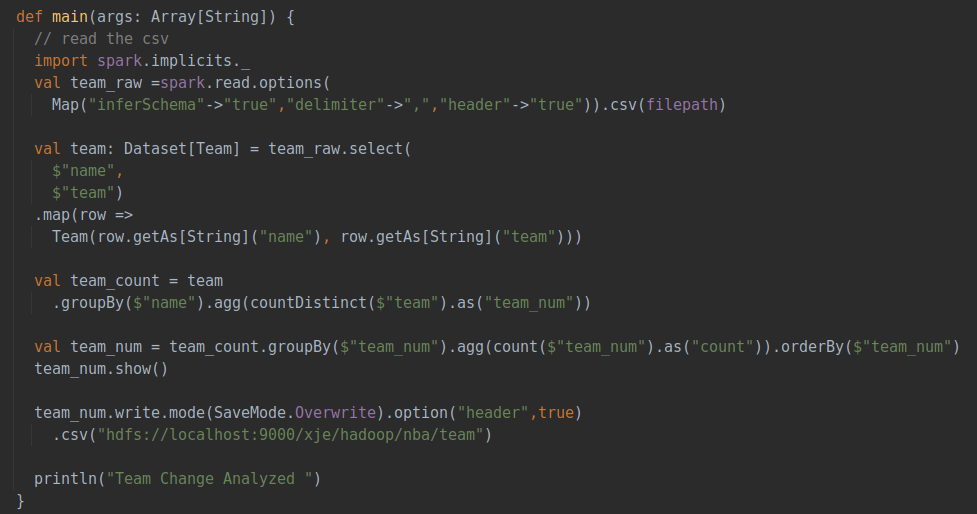
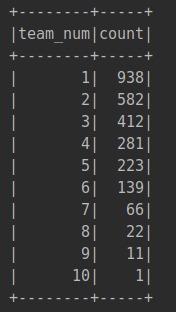
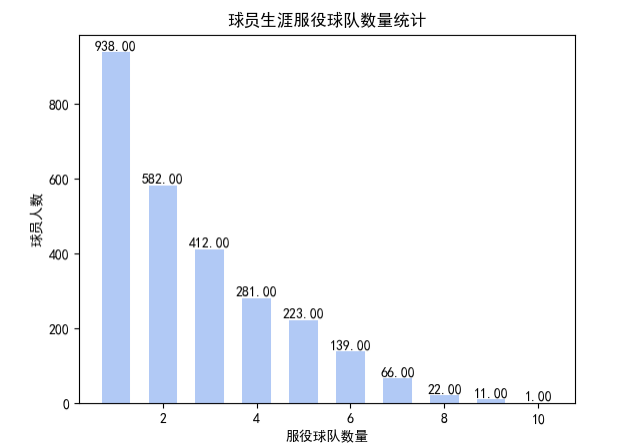
該部分分析不同球員在聯(lián)盟中更換隊伍的情況,即對每個球員所在隊伍的種類數(shù)量進行統(tǒng)計,具體流程如下: ①讀取csv數(shù)據(jù)集 ②選出name和team字段創(chuàng)建Dataset類 ③按照不同球員的名字進行分組,對每一球員隊伍出現(xiàn)的種類數(shù)量進行統(tǒng)計 ④對于統(tǒng)計后的每個球員的隊伍數(shù)再次進行聚合統(tǒng)計 ⑤保存處理完的數(shù)據(jù) 具體代碼如下:
主要使用Dataset類的GroupBy和agg作對數(shù)據(jù)進行分組和聚類,最終統(tǒng)計出總的隊伍變更數(shù)量,輸出時按照隊伍的數(shù)量進行排序,運行后的輸出結(jié)果如下圖:
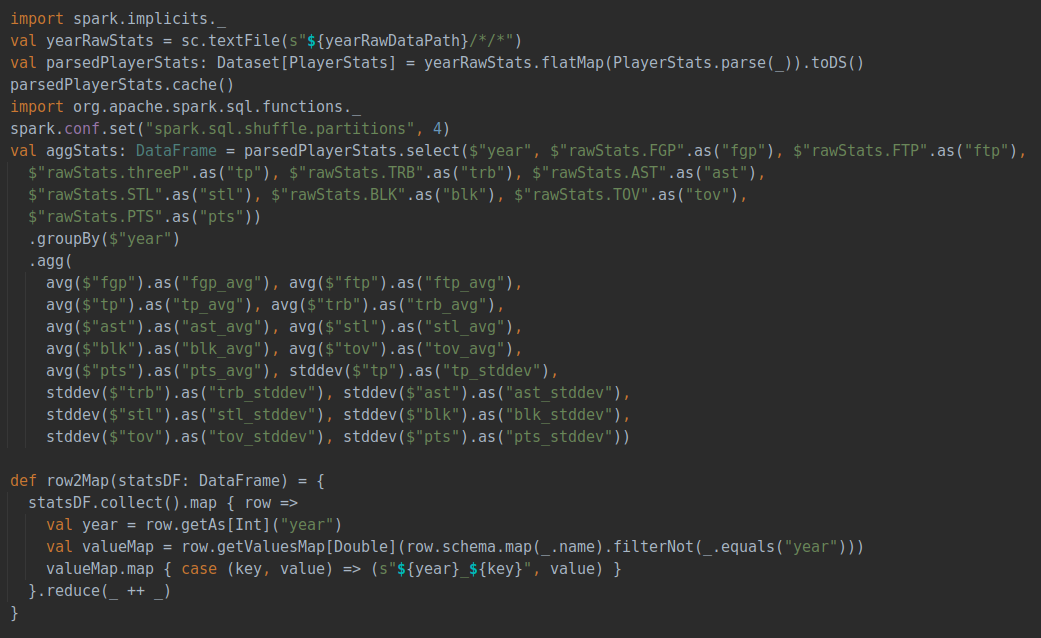
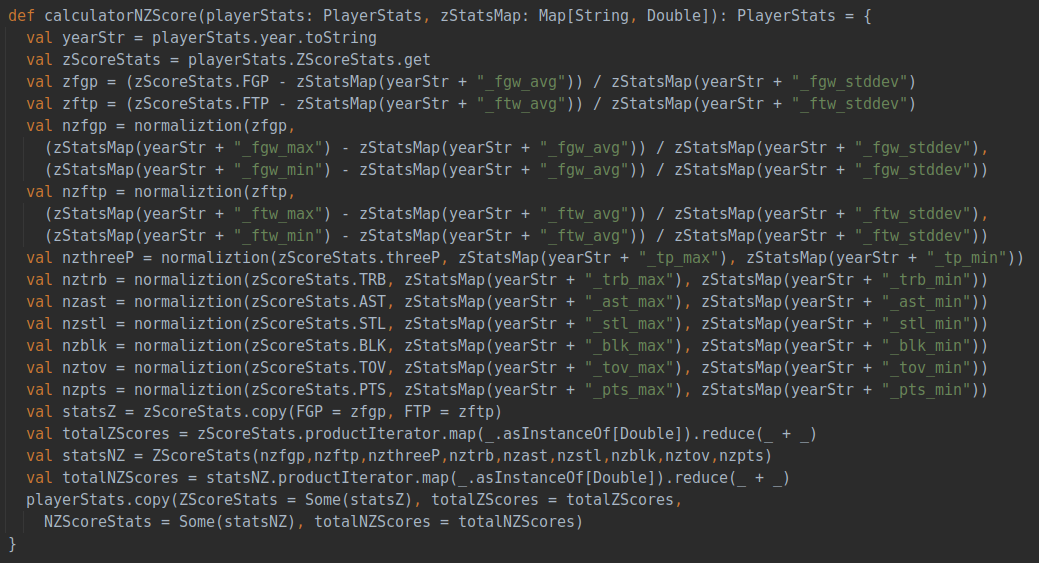
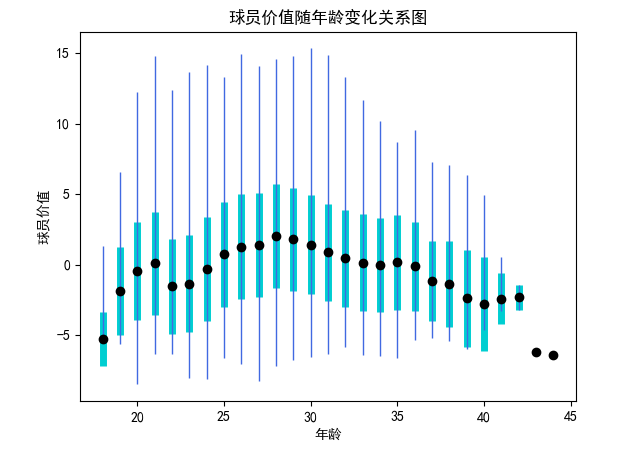
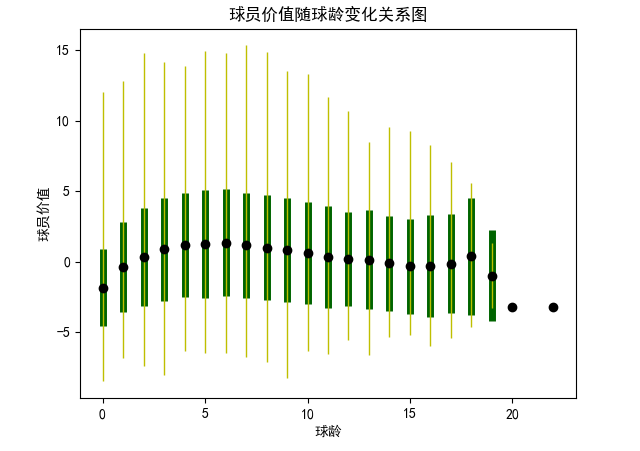
該部分分析球員的價值與年齡和球齡之間關(guān)系,首先需要對球員價值有一個量化的評估,這部分是已經(jīng)在數(shù)據(jù)預處理中提到的zScore的計算, zScore是結(jié)合三分球命中數(shù)、籃板總數(shù)、助攻總數(shù)、搶斷總數(shù)、蓋帽總數(shù)、失誤總數(shù)、得分總數(shù)共計七個指標進行評估,nzScore是在此基礎(chǔ)之上增加投籃命中率、罰球命中率兩個指標共計九個指標進行評估。計算代碼如下:
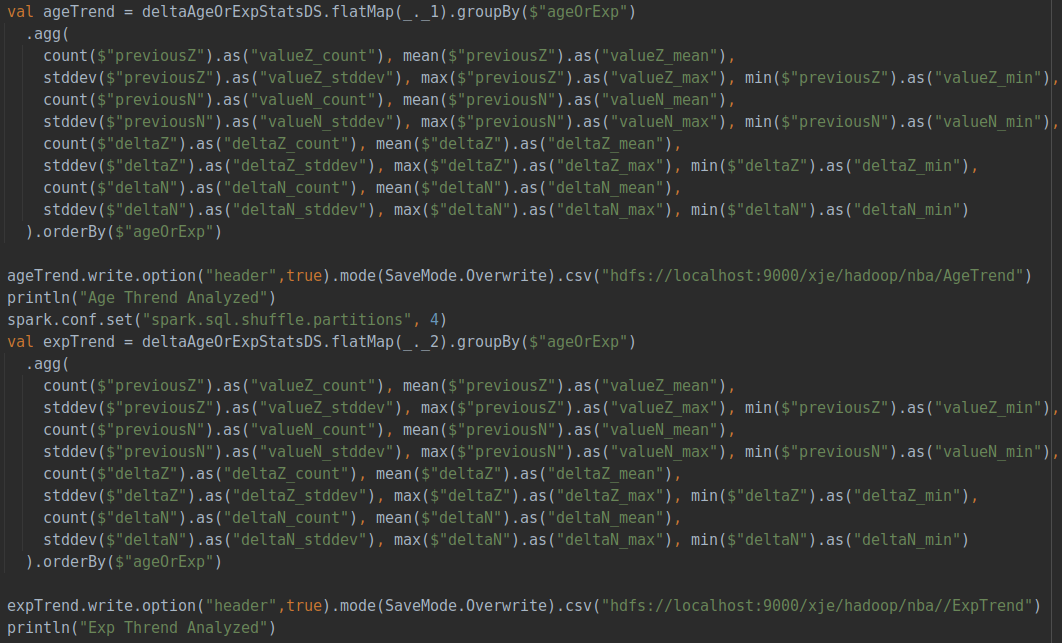
所有的各項指標會與當年所有數(shù)據(jù)計算出的平均數(shù)和標準方差進行標準化,保證每個數(shù)據(jù)在同一尺度并確保每一年的評價指標相對齊,在獲得每個球員每一年的評價得分之后,隨著年份變化對球員的價值變化進行評估并聚合,得到隨著年齡或是球齡變化時球員價值的變化關(guān)系。具體代碼如下:
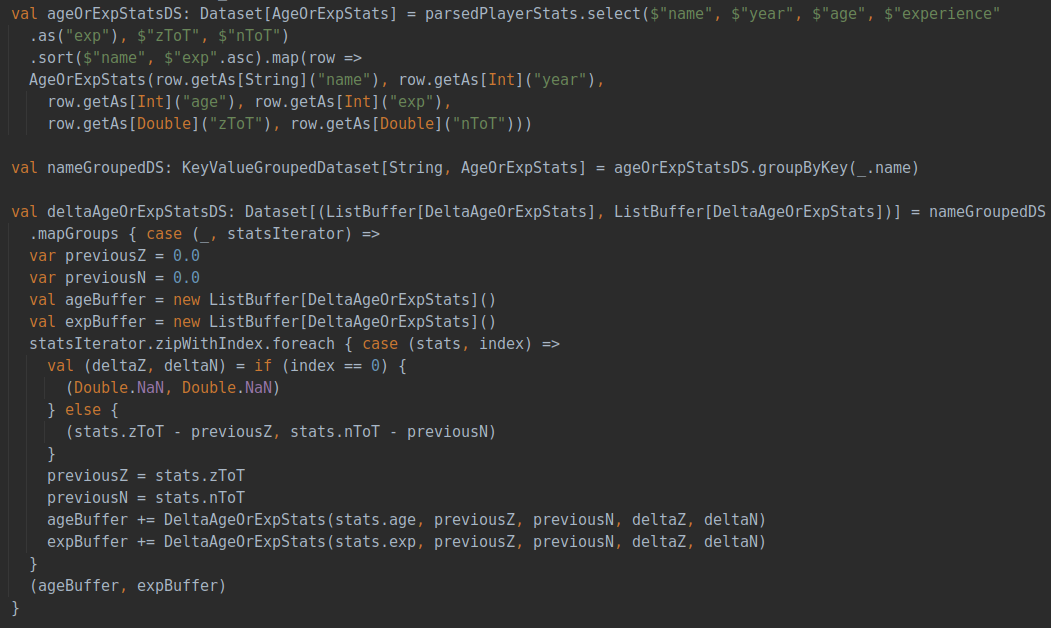
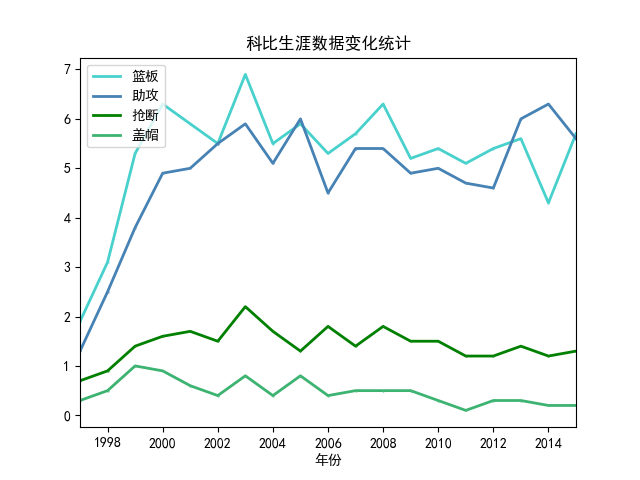
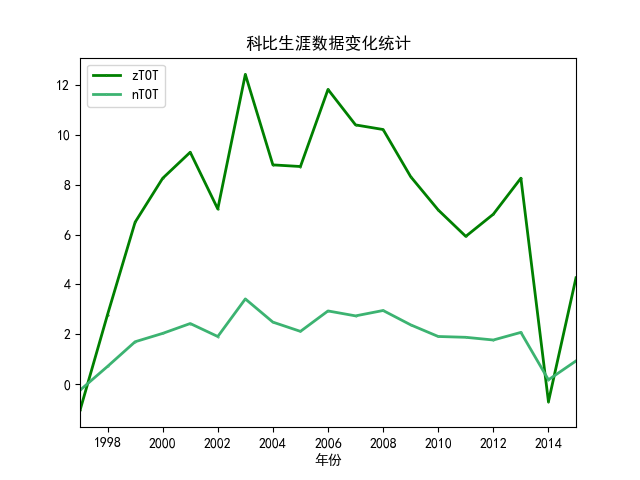
這部分分析任意一名球員在不同賽季的數(shù)據(jù)變化,再根據(jù)已經(jīng)計算出的球員價值zScore同步分析球員的數(shù)據(jù)隨著賽季不斷發(fā)展中發(fā)生的變化。同樣先利用spark讀入已經(jīng)預處理好的csv文件,再通過sql的select方法從指定球員的數(shù)據(jù)中篩選出所需要的字段,具體代碼如下:
對結(jié)果數(shù)據(jù)的可視化使用python語言,具體所用的版本及庫如下: ?Python 3.10.4 ?Pandas ?Matplotlib (2)主要數(shù)據(jù)排行可視化結(jié)果
|
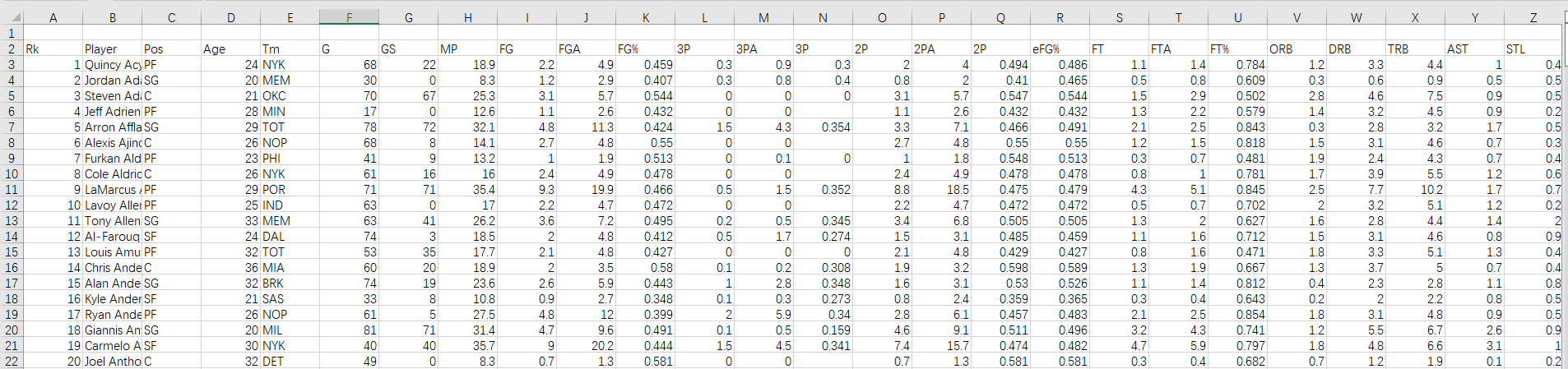

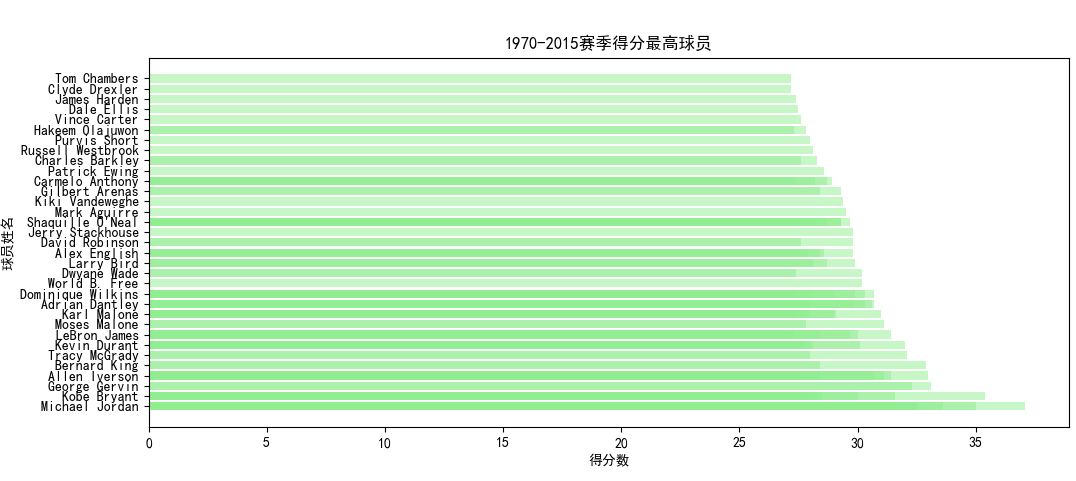
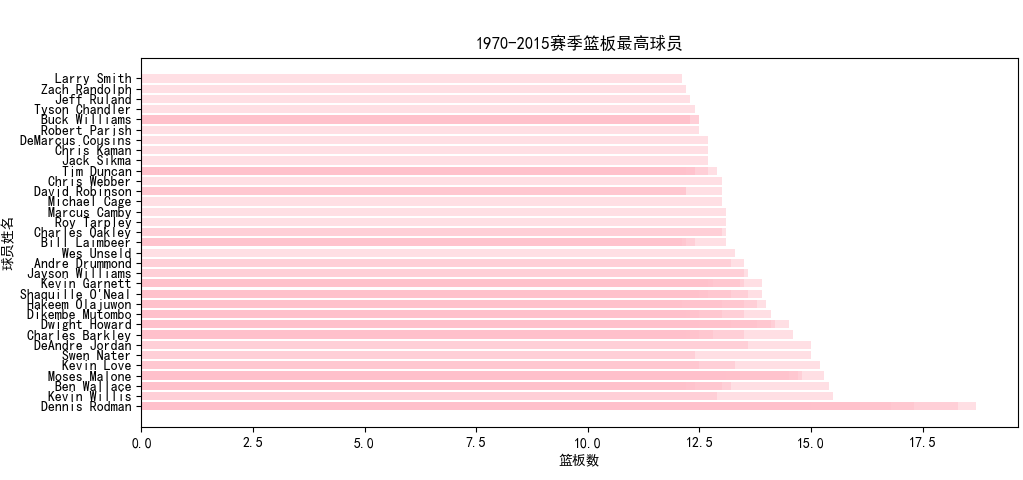
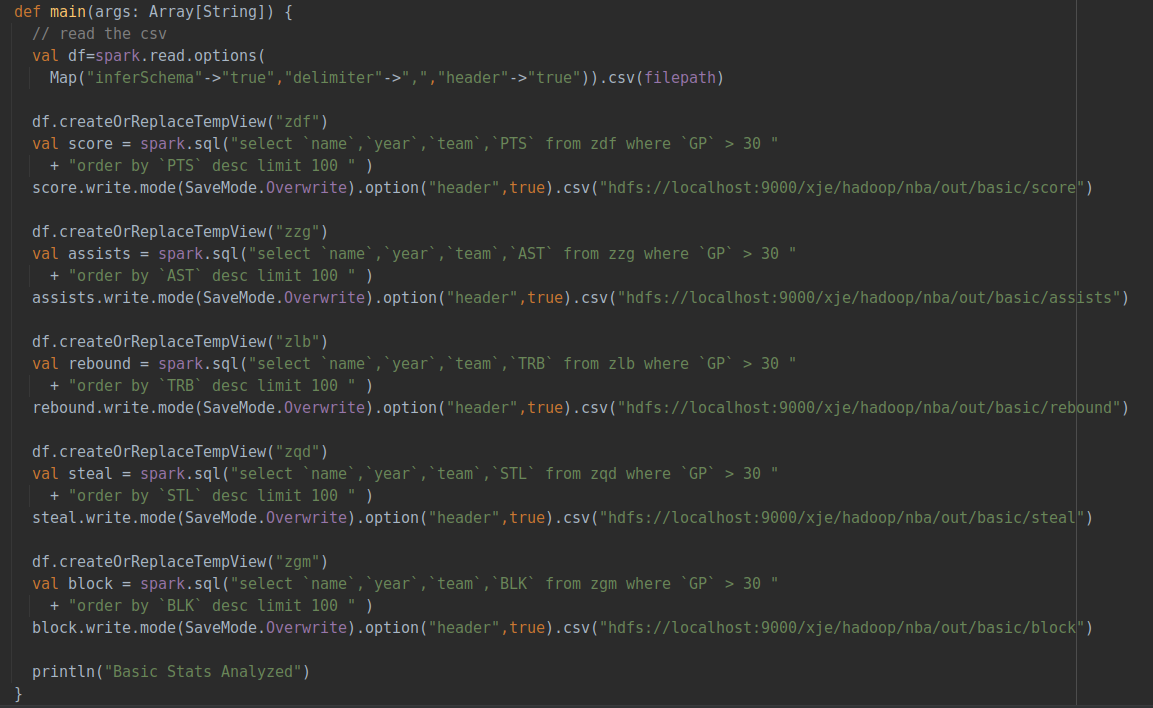 使用spark.sql語句從數(shù)據(jù)庫中select出球員姓名、年份、所在隊伍以及待分析的數(shù)據(jù)(包括得分、籃板、助攻、蓋帽、搶斷),同時通過GP也就是出場數(shù)進行篩選,必須滿足出場數(shù)大于30,防止統(tǒng)計到低出場數(shù)的不可靠數(shù)據(jù)。
按照得分或籃板等數(shù)據(jù)進行降序排序后進行輸出,并寫入csv中存儲至HDFS。
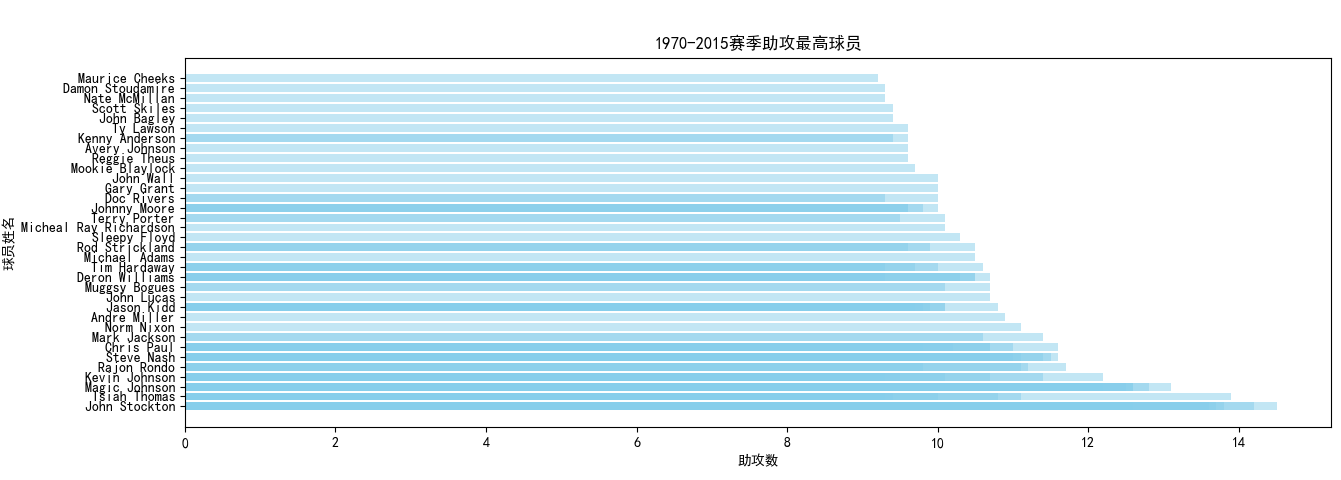
使用spark.sql語句從數(shù)據(jù)庫中select出球員姓名、年份、所在隊伍以及待分析的數(shù)據(jù)(包括得分、籃板、助攻、蓋帽、搶斷),同時通過GP也就是出場數(shù)進行篩選,必須滿足出場數(shù)大于30,防止統(tǒng)計到低出場數(shù)的不可靠數(shù)據(jù)。
按照得分或籃板等數(shù)據(jù)進行降序排序后進行輸出,并寫入csv中存儲至HDFS。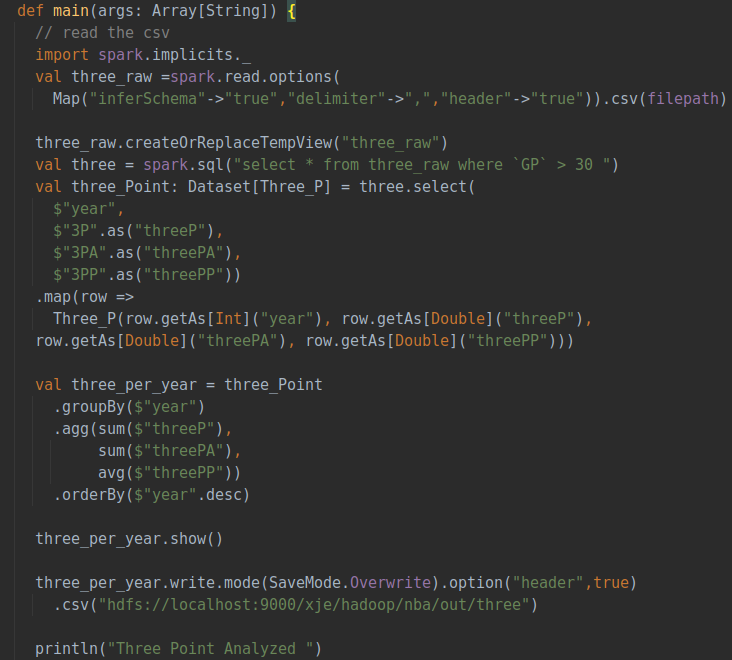
【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |