| LSTM從入門到精通(形象的圖解,詳細(xì)的代碼和注釋,完美的數(shù)學(xué)推導(dǎo)過程) | 您所在的位置:網(wǎng)站首頁 › 屬狗生于十二月 › LSTM從入門到精通(形象的圖解,詳細(xì)的代碼和注釋,完美的數(shù)學(xué)推導(dǎo)過程) |
LSTM從入門到精通(形象的圖解,詳細(xì)的代碼和注釋,完美的數(shù)學(xué)推導(dǎo)過程)

先附上這篇文章的一個(gè)思維導(dǎo)圖  什么是RNN
按照八股文來說:RNN實(shí)際上就是一個(gè)帶有
記憶的時(shí)間序列的預(yù)測(cè)模型
什么是RNN
按照八股文來說:RNN實(shí)際上就是一個(gè)帶有
記憶的時(shí)間序列的預(yù)測(cè)模型
RNN的細(xì)胞結(jié)構(gòu)圖如下: 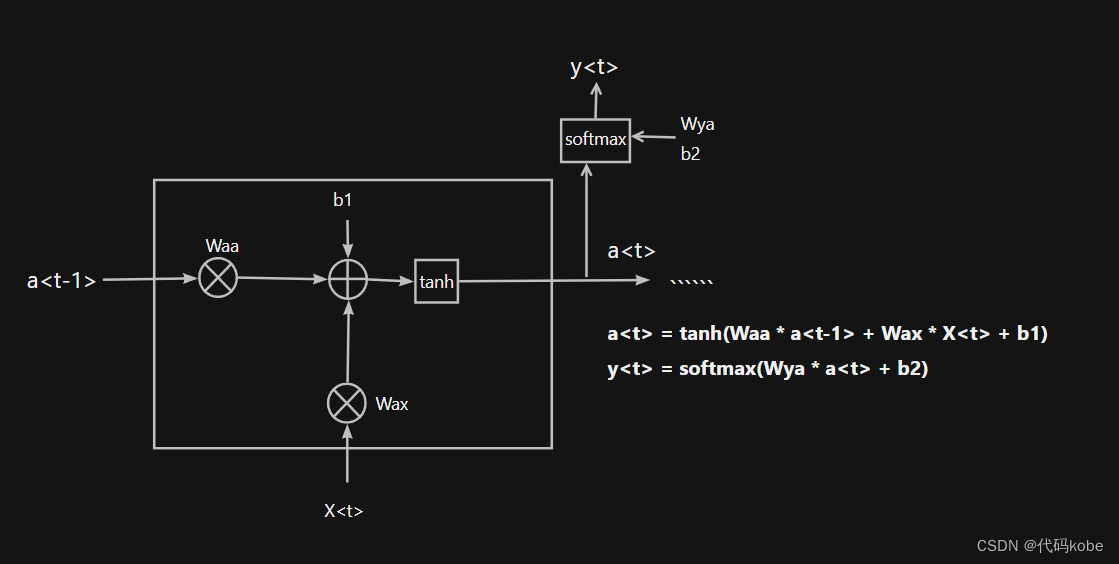 softmax激活函數(shù)只是我舉的一個(gè)例子,實(shí)際上得到y(tǒng)也可以通過其他的激活函數(shù)得到
softmax激活函數(shù)只是我舉的一個(gè)例子,實(shí)際上得到y(tǒng)也可以通過其他的激活函數(shù)得到
其中a代表t-1時(shí)刻隱藏狀態(tài),a代表經(jīng)過X這一t時(shí)刻的輸入之后,得到的新的隱藏狀態(tài)。公式主要是a = tanh(Waa * a + Wax * X + b1) ;大白話解釋一下就是,X是今天的吊針,a是昨天的發(fā)燒度數(shù)39,經(jīng)過今天這一針之后,a變成38度。這里的記憶體現(xiàn)在今天的38度是在前一天的基礎(chǔ)上,通過打吊針來達(dá)到第二天的降溫狀態(tài)。 1.1 RNN的應(yīng)用由于RNN的記憶性,我們最容易想到的就是RNN在自然語言處理方面的應(yīng)用,譬如下面這張圖,提前預(yù)測(cè)出下一個(gè)字。 
除此之外,RNN的應(yīng)用還包括下面的方向: 語言模型:RNN被廣泛應(yīng)用于語言模型的建模中,例如自然語言處理、機(jī)器翻譯、語音識(shí)別等領(lǐng)域。 時(shí)間序列預(yù)測(cè):RNN可以用于時(shí)間序列預(yù)測(cè),例如股票價(jià)格預(yù)測(cè)、氣象預(yù)測(cè)、心電圖信號(hào)預(yù)測(cè)等。 生成模型:RNN可以用于生成模型,例如文本生成、音樂生成、藝術(shù)創(chuàng)作等。 強(qiáng)化學(xué)習(xí):RNN可以用于強(qiáng)化學(xué)習(xí)中,例如在游戲、機(jī)器人控制和決策制定等領(lǐng)域。 1.2 RNN的缺陷 想必大家一定聽說過LSTM,沒錯(cuò),就是由于RNN的尿性,所以才出現(xiàn)LSTM這一更精妙的時(shí)間序列預(yù)測(cè)模型的設(shè)計(jì)。但是我們知己知彼才能百戰(zhàn)百勝,因此我還是決定詳細(xì)分析一下RNN的缺陷,看過一些資料,但是只是膚淺的提到了梯度消失和梯度爆炸,沒有實(shí)際的數(shù)學(xué)推導(dǎo),這可不是一個(gè)求學(xué)之人應(yīng)該有的態(tài)度!主要的缺陷是兩個(gè): 長期依賴問題導(dǎo)致的梯度消失:眾所周知RNN模型是一個(gè)具有記憶的模型,每一次的預(yù)測(cè)都和當(dāng)前輸入以及之前的狀態(tài)有關(guān),但是我們?cè)囅耄绻覀兊木渥雍荛L,他在第1000個(gè)記憶細(xì)胞還能記住并很好的利用第1個(gè)細(xì)胞的記憶狀態(tài)嗎?答案顯然是否定的 梯度爆炸 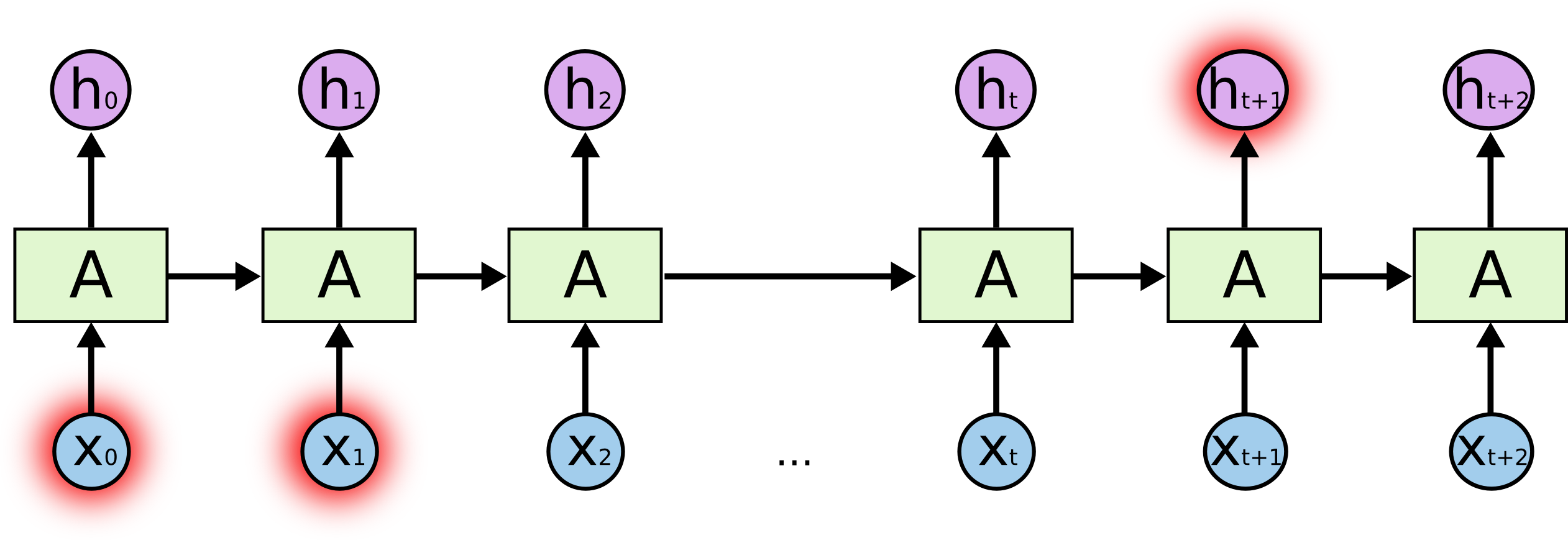 1.2.1 梯度消失和梯度爆炸的詳細(xì)公式推導(dǎo)
1.2.1 梯度消失和梯度爆炸的詳細(xì)公式推導(dǎo)
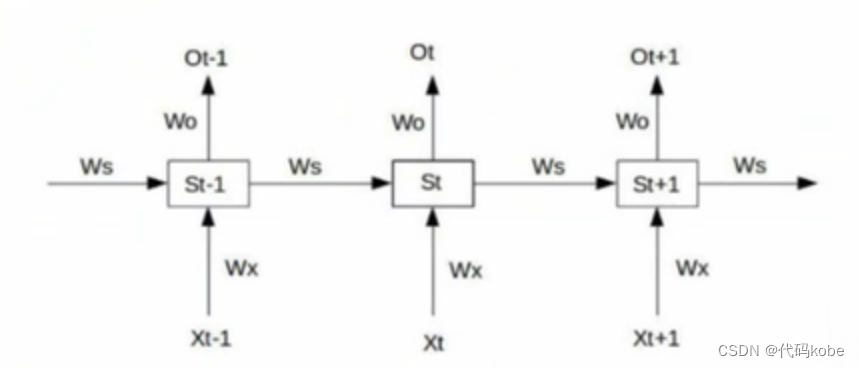
敲黑板(手寫公式推導(dǎo),大家最迷糊的地方): 根據(jù)下面圖示的例子,我手寫并反復(fù)檢查了自己的過程(下圖),請(qǐng)各位看官務(wù)必認(rèn)真看看,理解起來并不難,對(duì)于別的文章隨口一提的梯度消失和梯度爆炸實(shí)在是透徹太多啦!!! 我們假設(shè)損失函數(shù)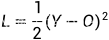 ,Y是實(shí)際值,O是預(yù)測(cè)值;首先,我們假設(shè)只有
三層,然后通過三層我們就能以此類推找出規(guī)律。反向傳播我們需要對(duì)Wo,Wx,Ws,b四個(gè)變量都求偏導(dǎo),在這里我們主要對(duì)Wx求偏導(dǎo),其他三個(gè)以此類推,就很簡單了。為了表示更清晰,筆者使用紫色的x表示乘法。 ,Y是實(shí)際值,O是預(yù)測(cè)值;首先,我們假設(shè)只有
三層,然后通過三層我們就能以此類推找出規(guī)律。反向傳播我們需要對(duì)Wo,Wx,Ws,b四個(gè)變量都求偏導(dǎo),在這里我們主要對(duì)Wx求偏導(dǎo),其他三個(gè)以此類推,就很簡單了。為了表示更清晰,筆者使用紫色的x表示乘法。
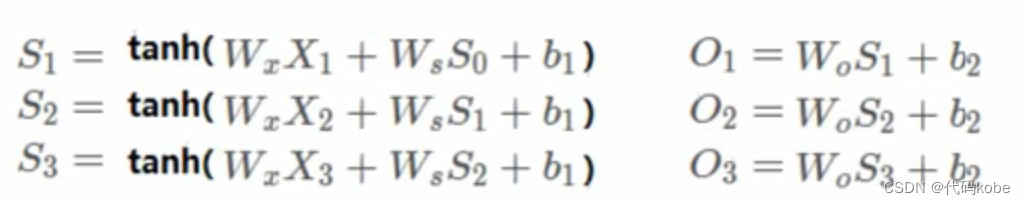

根據(jù)推導(dǎo)的公式我們得到一個(gè)指數(shù)函數(shù) 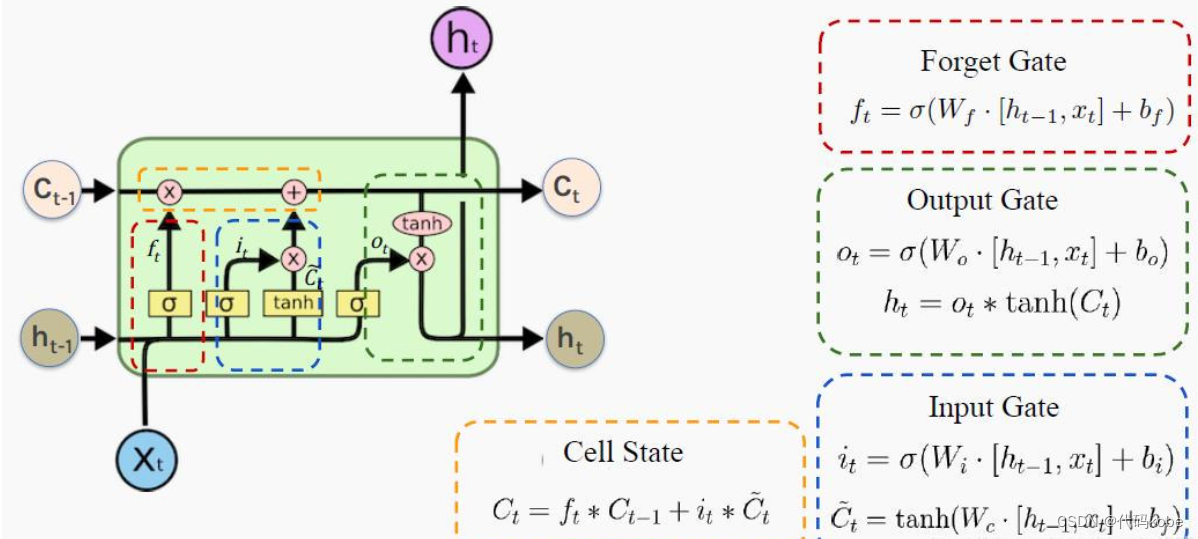 Ct是細(xì)胞狀態(tài)(記憶狀態(tài)),
Ct是細(xì)胞狀態(tài)(記憶狀態(tài)),
 是輸入的信息, 是輸入的信息,
 是隱藏狀態(tài)(基于 是隱藏狀態(tài)(基于
 得到的) 得到的)
用最樸素的語言解釋一下三個(gè)門,并且用兩門考試來形象的解釋一下LSTM: 遺忘門:通過x和ht的作,并經(jīng)過sigmoid函數(shù),得到0,1的向量,0對(duì)應(yīng)的就代表之前的記憶某一部分要忘記,1對(duì)應(yīng)的就代表之前的記憶需要留下的部分 ===> 輸入門:通過將之前的需要留下的信息和現(xiàn)在需要記住的信息相加,也就是得到了新的記憶狀態(tài)。===> 輸出門:整合 為了便于大家理解,附上幾張非常好的圖供大家理解完整的數(shù)據(jù)處理的流程: 遺忘門: 
輸入門: 
細(xì)胞狀態(tài): 
輸出門:  2.1 LSTM的模型結(jié)構(gòu)
2.1 LSTM的模型結(jié)構(gòu)
這里有兩張別的博主的很好的圖,我在初學(xué)的時(shí)候也是恍然大悟: 圖的出處 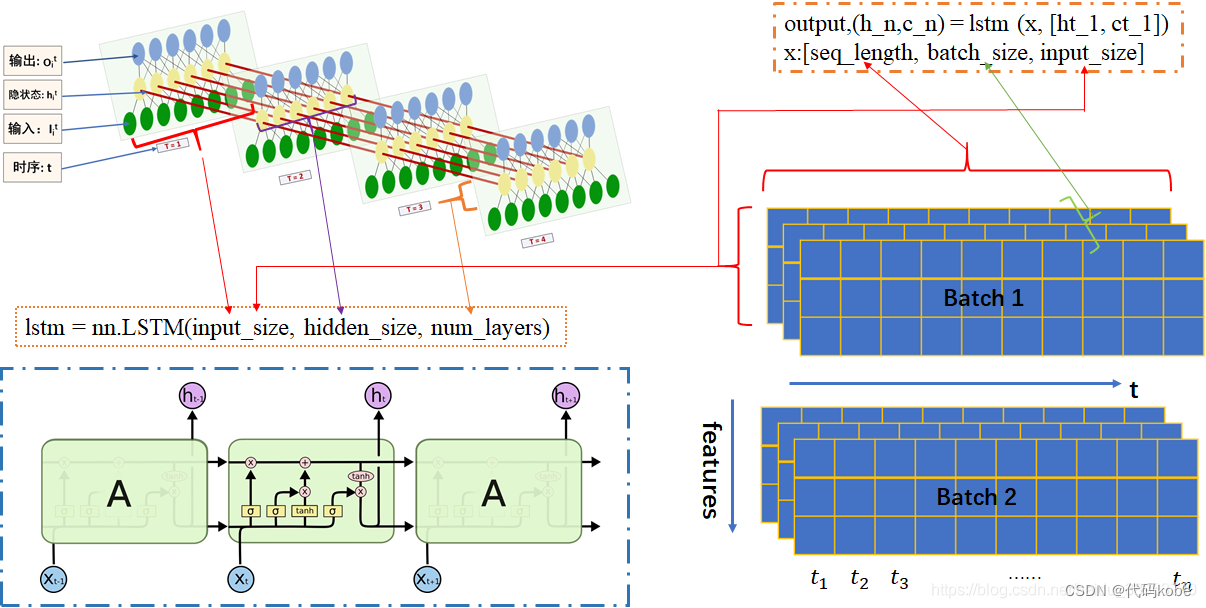
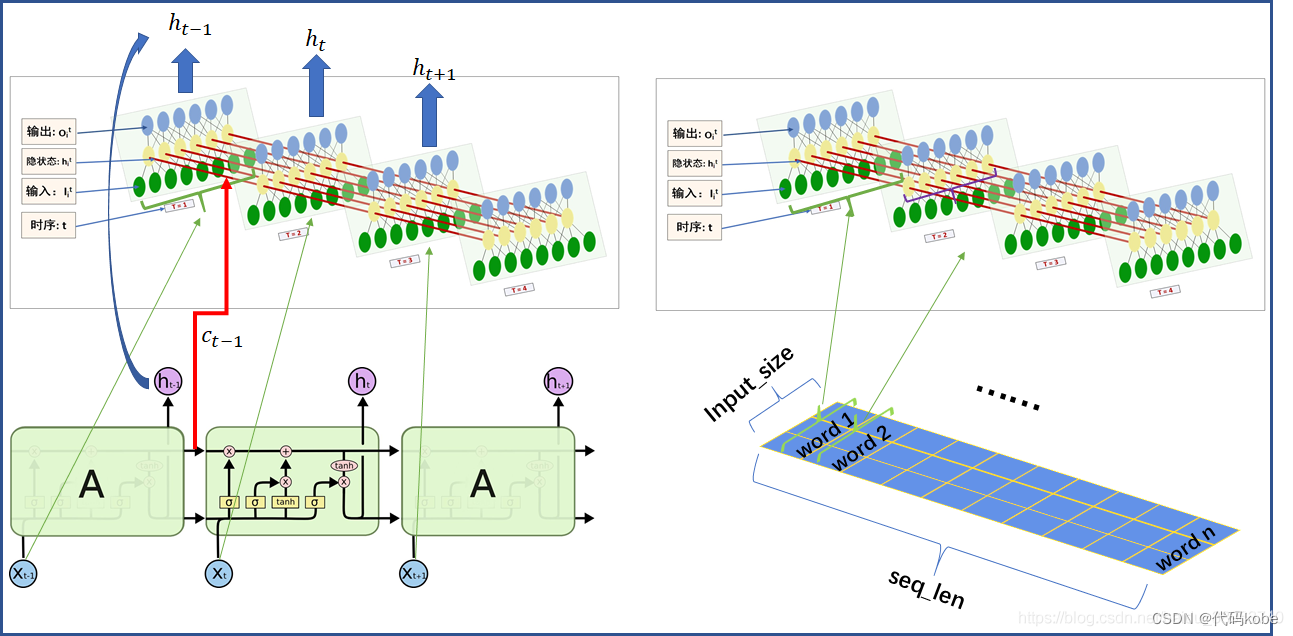
解釋一下pytorch訓(xùn)練lstm所使用的參數(shù): 這是利用pytorch調(diào)用LSTM所使用的參數(shù) output,(h_n,c_n) = lstm (x, [ht_1, ct_1]),一般直接放入x就好,后面中括號(hào)的不用管這是作為x(輸入)喂給LSTM的參數(shù) x:[seq_length, batch_size, input_size],這里有點(diǎn)反人類,batch_size一般都是放在開始的位置這是pytorch簡歷LSTM是所需參數(shù) lstm = LSTM(input_size,hidden_size,num_layers) 2.2 LSTM相比RNN的優(yōu)勢(shì)LSTM的反向傳播的數(shù)學(xué)推導(dǎo)很繁瑣,因?yàn)樯婕暗降淖兞亢芏啵荓STM確實(shí)是可以在一定程度上解決梯度消失和梯度爆炸的問題。我簡單說一下,RNN的連乘主要是W的連乘,而W是一樣的,因此就是一個(gè)指數(shù)函數(shù)(在梯度中出現(xiàn)指數(shù)函數(shù)并不是一件友好的事情);相反,LSTM的連乘是 需要安裝一下tushare的金融方面的數(shù)據(jù)集,代碼的注解我已經(jīng)寫的很清楚了 #!/usr/bin/python3 # -*- encoding: utf-8 -*- import matplotlib.pyplot as plt import numpy as np import tushare as ts import pandas as pd import torch from torch import nn import datetime import time DAYS_FOR_TRAIN = 10 class LSTM_Regression(nn.Module): """ 使用LSTM進(jìn)行回歸 參數(shù): - input_size: feature size - hidden_size: number of hidden units - output_size: number of output - num_layers: layers of LSTM to stack """ def __init__(self, input_size, hidden_size, output_size=1, num_layers=2): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, num_layers) self.fc = nn.Linear(hidden_size, output_size) def forward(self, _x): x, _ = self.lstm(_x) # _x is input, size (seq_len, batch, input_size) s, b, h = x.shape x = x.view(s * b, h) x = self.fc(x) x = x.view(s, b, -1) # 把形狀改回來 return x def create_dataset(data, days_for_train=5) -> (np.array, np.array): """ 根據(jù)給定的序列data,生成數(shù)據(jù)集 數(shù)據(jù)集分為輸入和輸出,每一個(gè)輸入的長度為days_for_train,每一個(gè)輸出的長度為1。 也就是說用days_for_train天的數(shù)據(jù),對(duì)應(yīng)下一天的數(shù)據(jù)。 若給定序列的長度為d,將輸出長度為(d-days_for_train+1)個(gè)輸入/輸出對(duì) """ dataset_x, dataset_y = [], [] for i in range(len(data) - days_for_train): _x = data[i:(i + days_for_train)] dataset_x.append(_x) dataset_y.append(data[i + days_for_train]) return (np.array(dataset_x), np.array(dataset_y)) if __name__ == '__main__': t0 = time.time() data_close = ts.get_k_data('000001', start='2019-01-01', index=True)['close'] # 取上證指數(shù)的收盤價(jià) data_close.to_csv('000001.csv', index=False) #將下載的數(shù)據(jù)轉(zhuǎn)存為.csv格式保存 data_close = pd.read_csv('000001.csv') # 讀取文件 df_sh = ts.get_k_data('sh', start='2019-01-01', end=datetime.datetime.now().strftime('%Y-%m-%d')) print(df_sh.shape) data_close = data_close.astype('float32').values # 轉(zhuǎn)換數(shù)據(jù)類型 plt.plot(data_close) plt.savefig('data.png', format='png', dpi=200) plt.close() # 將價(jià)格標(biāo)準(zhǔn)化到0~1 max_value = np.max(data_close) min_value = np.min(data_close) data_close = (data_close - min_value) / (max_value - min_value) # dataset_x # 是形狀為(樣本數(shù), 時(shí)間窗口大小) # 的二維數(shù)組,用于訓(xùn)練模型的輸入 # dataset_y # 是形狀為(樣本數(shù), ) # 的一維數(shù)組,用于訓(xùn)練模型的輸出。 dataset_x, dataset_y = create_dataset(data_close, DAYS_FOR_TRAIN) # 分別是(1007,10,1)(1007,1) # 劃分訓(xùn)練集和測(cè)試集,70%作為訓(xùn)練集 train_size = int(len(dataset_x) * 0.7) train_x = dataset_x[:train_size] train_y = dataset_y[:train_size] # 將數(shù)據(jù)改變形狀,RNN 讀入的數(shù)據(jù)維度是 (seq_size, batch_size, feature_size) train_x = train_x.reshape(-1, 1, DAYS_FOR_TRAIN) train_y = train_y.reshape(-1, 1, 1) # 轉(zhuǎn)為pytorch的tensor對(duì)象 train_x = torch.from_numpy(train_x) train_y = torch.from_numpy(train_y) model = LSTM_Regression(DAYS_FOR_TRAIN, 8, output_size=1, num_layers=2) # 導(dǎo)入模型并設(shè)置模型的參數(shù)輸入輸出層、隱藏層等 model_total = sum([param.nelement() for param in model.parameters()]) # 計(jì)算模型參數(shù) print("Number of model_total parameter: %.8fM" % (model_total / 1e6)) train_loss = [] loss_function = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-2, betas=(0.9, 0.999), eps=1e-08, weight_decay=0) for i in range(200): out = model(train_x) loss = loss_function(out, train_y) loss.backward() optimizer.step() optimizer.zero_grad() train_loss.append(loss.item()) # 將訓(xùn)練過程的損失值寫入文檔保存,并在終端打印出來 with open('log.txt', 'a+') as f: f.write('{} - {}\n'.format(i + 1, loss.item())) if (i + 1) % 1 == 0: print('Epoch: {}, Loss:{:.5f}'.format(i + 1, loss.item())) # 畫loss曲線 plt.figure() plt.plot(train_loss, 'b', label='loss') plt.title("Train_Loss_Curve") plt.ylabel('train_loss') plt.xlabel('epoch_num') plt.savefig('loss.png', format='png', dpi=200) plt.close() # torch.save(model.state_dict(), 'model_params.pkl') # 可以保存模型的參數(shù)供未來使用 t1 = time.time() T = t1 - t0 print('The training time took %.2f' % (T / 60) + ' mins.') tt0 = time.asctime(time.localtime(t0)) tt1 = time.asctime(time.localtime(t1)) print('The starting time was ', tt0) print('The finishing time was ', tt1) # for test model = model.eval() # 轉(zhuǎn)換成評(píng)估模式 # model.load_state_dict(torch.load('model_params.pkl')) # 讀取參數(shù) # 注意這里用的是全集 模型的輸出長度會(huì)比原數(shù)據(jù)少DAYS_FOR_TRAIN 填充使長度相等再作圖 dataset_x = dataset_x.reshape(-1, 1, DAYS_FOR_TRAIN) # (seq_size, batch_size, feature_size) dataset_x = torch.from_numpy(dataset_x) pred_test = model(dataset_x) # 全量訓(xùn)練集 # 的模型輸出 (seq_size, batch_size, output_size) pred_test = pred_test.view(-1).data.numpy() pred_test = np.concatenate((np.zeros(DAYS_FOR_TRAIN), pred_test)) # 填充0 使長度相同 assert len(pred_test) == len(data_close) plt.plot(pred_test, 'r', label='prediction') plt.plot(data_close, 'b', label='real') plt.plot((train_size, train_size), (0, 1), 'g--') # 分割線 左邊是訓(xùn)練數(shù)據(jù) 右邊是測(cè)試數(shù)據(jù)的輸出 plt.legend(loc='best') plt.savefig('result.png', format='png', dpi=200) plt.close()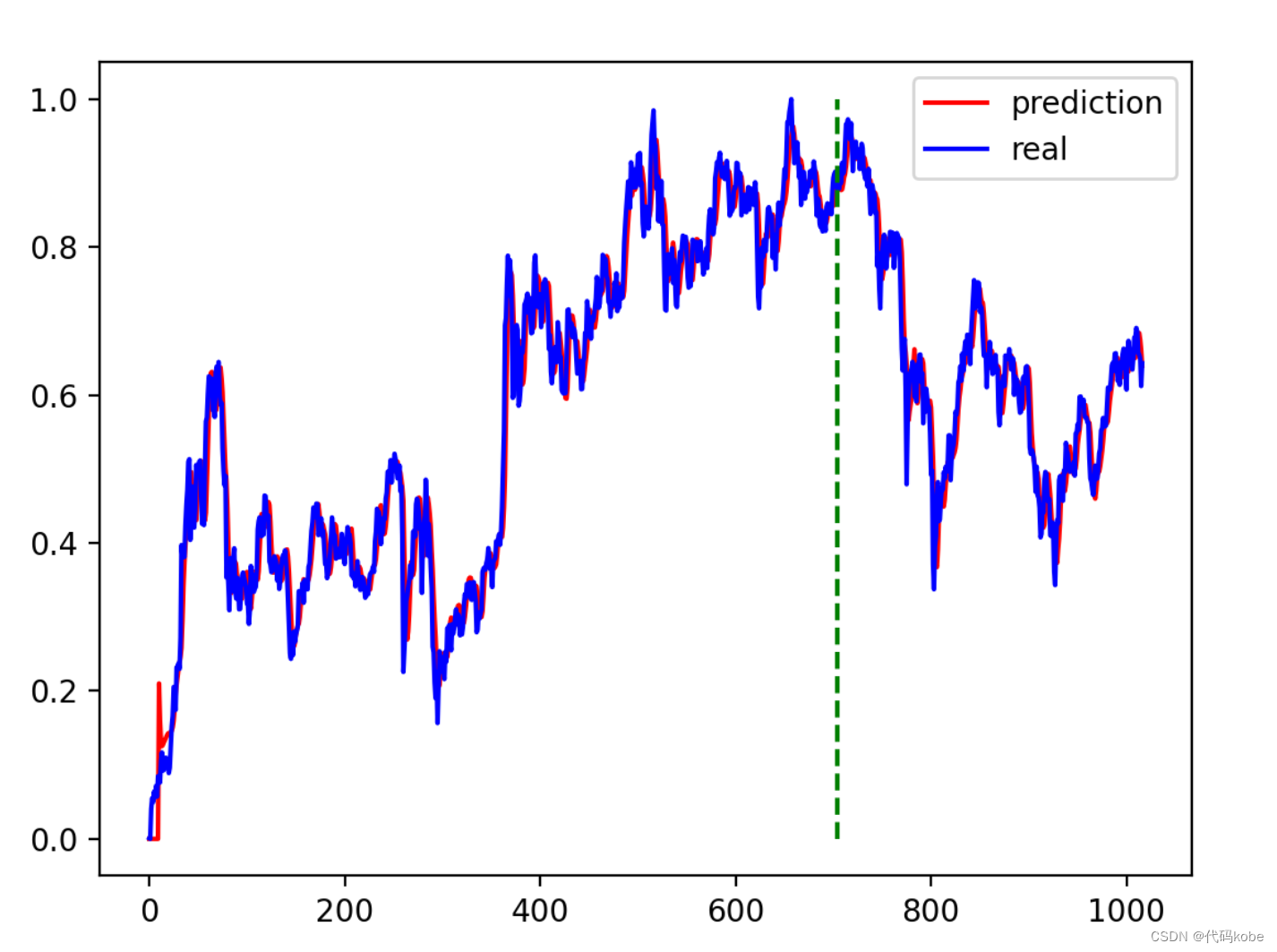 2.4 小問題:為什么采用tanh函數(shù),不能都用sigmoid函數(shù)嗎
2.4 小問題:為什么采用tanh函數(shù),不能都用sigmoid函數(shù)嗎
先放上兩個(gè)函數(shù)的圖形: 
Sigmoid函數(shù)比Tanh函數(shù)收斂飽和速度慢 Sigmoid函數(shù)比Tanh函數(shù)值域范圍更窄 tanh的均值是0,Sigmoid均值在0.5左右,均值在0的數(shù)據(jù)顯然更便于數(shù)據(jù)處理 tanh的函數(shù)變化敏感區(qū)間更大 對(duì)兩者求導(dǎo),發(fā)現(xiàn)tanh對(duì)計(jì)算的壓力更小,直接是1-原函數(shù)的平方,不需要指數(shù)作 使用該問的圖請(qǐng)標(biāo)明出處,創(chuàng)作不易,希望收獲你的贊贊 |
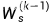 ,我們?cè)诟咧袝r(shí)候就學(xué)到過指數(shù)函數(shù)的變化系數(shù)是極大的,因此在t趨于比較大的時(shí)候(也就是我們的句子比較長的時(shí)候),如果
,我們?cè)诟咧袝r(shí)候就學(xué)到過指數(shù)函數(shù)的變化系數(shù)是極大的,因此在t趨于比較大的時(shí)候(也就是我們的句子比較長的時(shí)候),如果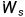 比1小不少,那么模型的一部分梯度會(huì)趨于0,因此優(yōu)化會(huì)幾乎停止;同理,如果
比1小不少,那么模型的一部分梯度會(huì)趨于0,因此優(yōu)化會(huì)幾乎停止;同理,如果 代表復(fù)習(xí)上一門線性代數(shù)所包含的記憶,通過遺忘門,忘記掉和下一門高等數(shù)學(xué)無關(guān)的內(nèi)容(比如矩陣的秩)
代表復(fù)習(xí)上一門線性代數(shù)所包含的記憶,通過遺忘門,忘記掉和下一門高等數(shù)學(xué)無關(guān)的內(nèi)容(比如矩陣的秩)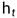 則代表實(shí)際的考試分?jǐn)?shù)
則代表實(shí)際的考試分?jǐn)?shù)【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |