| DeepSeek | 您所在的位置:網(wǎng)站首頁(yè) › 屬牛的女和狗男人相配怎么樣 › DeepSeek |
DeepSeek
|
DeepSeek-R1 更新,思考更深,推理更強(qiáng)
DeepSeek R1 模型已完成小版本升級(jí),當(dāng)前版本為 DeepSeek-R1-0528。用戶通過官方網(wǎng)站、APP 或小程序進(jìn)入對(duì)話界面后,開啟“深度思考”功能即可體驗(yàn)最新版本。API 也已同步更新,調(diào)用方式不變。 深度思考能力強(qiáng)化?DeepSeek-R1-0528 仍然使用 2024 年 12 月所發(fā)布的 DeepSeek V3 Base 模型作為基座,但在后訓(xùn)練過程中投入了更多算力,顯著提升了模型的思維深度與推理能力。 更新后的 R1 模型在數(shù)學(xué)、編程與通用邏輯等多個(gè)基準(zhǔn)測(cè)評(píng)中取得了當(dāng)前國(guó)內(nèi)所有模型中首屈一指的優(yōu)異成績(jī),并且在整體表現(xiàn)上已接近其他國(guó)際頂尖模型,如 o3 與 Gemini-2.5-Pro。 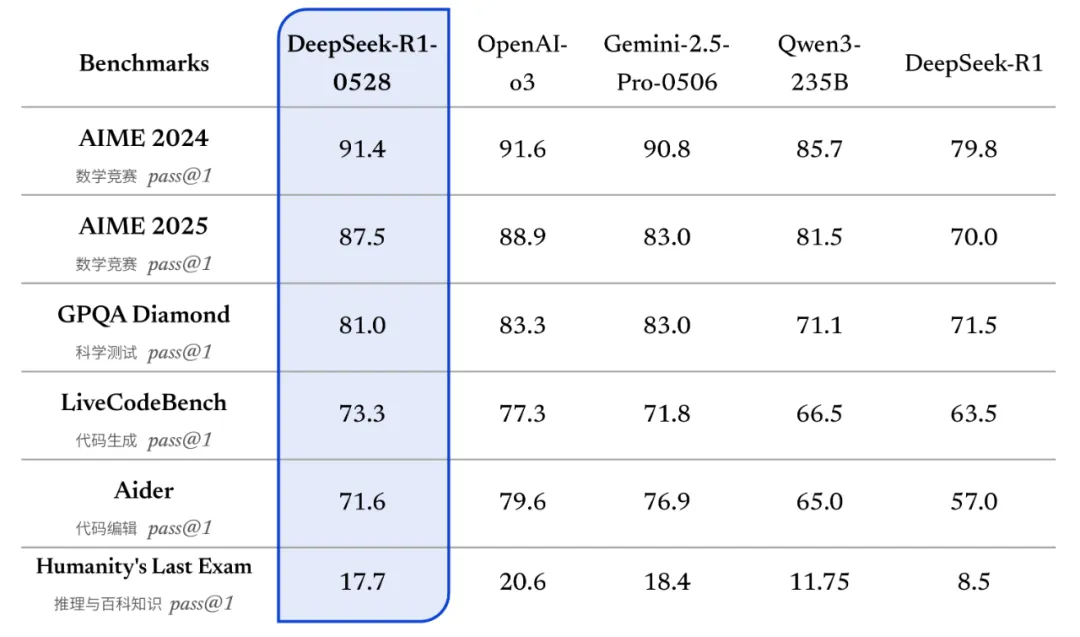
相較于舊版 R1,新版在復(fù)雜推理任務(wù)中的表現(xiàn)有了顯著提升。例如在 AIME 2025 測(cè)試中,新版模型準(zhǔn)確率由舊版的 70% 提升至 87.5%。這一進(jìn)步得益于模型在推理過程中的思維深度增強(qiáng):在 AIME 2025 測(cè)試集上,舊版模型平均每題使用 12K tokens,而新版模型平均每題使用 23K tokens,表明其在解題過程中進(jìn)行了更為詳盡和深入的思考。 同時(shí),我們蒸餾 DeepSeek-R1-0528 的思維鏈后訓(xùn)練 Qwen3-8B Base,得到了 DeepSeek-R1-0528-Qwen3-8B。該 8B 模型在數(shù)學(xué)測(cè)試 AIME 2024 中僅次于 DeepSeek-R1-0528,超越 Qwen3-8B (+10.0%),與 Qwen3-235B 相當(dāng)。我們相信,DeepSeek-R1-0528 的 |
【本文地址】