| 神經(jīng)網(wǎng)絡(luò)綜述 | 您所在的位置:網(wǎng)站首頁 › 射手座今天的運(yùn)勢如何女 › 神經(jīng)網(wǎng)絡(luò)綜述 |
神經(jīng)網(wǎng)絡(luò)綜述
|
1.人工智能、機(jī)器學(xué)習(xí)與深度學(xué)習(xí)
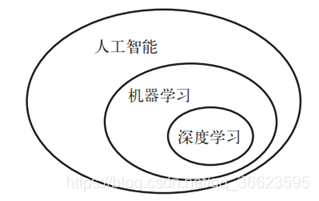
人工智能:努力將通常由人類完成的智力任務(wù)自動(dòng)化。機(jī)器學(xué)習(xí)機(jī)器學(xué)習(xí)( machine learning)是人工智能的一個(gè)特殊子領(lǐng)域,其目標(biāo)是僅靠觀察訓(xùn)練數(shù)據(jù)來自動(dòng)開發(fā)程序[即模型( model)]。深度學(xué)習(xí)是機(jī)器學(xué)習(xí)的一個(gè)分支領(lǐng)域:它是從數(shù)據(jù)中學(xué)習(xí)表示的一種新方法,強(qiáng)調(diào)從連續(xù)的層( layer)中進(jìn)行學(xué)習(xí)。“深度學(xué)習(xí)”中的“深度”指的并不是利用這種方法所獲取的更深層次的理解,而是指一系列連續(xù)的表示層。數(shù)據(jù)模型中包含多少層,這被稱為模型的深度( depth)。
人工智能、機(jī)器學(xué)習(xí)與深度學(xué)習(xí)關(guān)系如圖 1所示。在深度學(xué)習(xí)中,這些分層表示幾乎總是通過叫作神經(jīng)網(wǎng)絡(luò)( neural network)的模型來學(xué)習(xí)得到的。以下主要討論神經(jīng)網(wǎng)絡(luò)的分類? ? ? ?? 圖 1. 人工智能、機(jī)器學(xué)習(xí)與深度學(xué)習(xí) 人工神經(jīng)網(wǎng)絡(luò)(Artificial Neural Network,ANN)簡稱神經(jīng)網(wǎng)絡(luò)(NN),是基于生物學(xué)中神經(jīng)網(wǎng)絡(luò)的基本原理,在理解和抽象了人腦結(jié)構(gòu)和外界刺激響應(yīng)機(jī)制后,以網(wǎng)絡(luò)拓?fù)渲R(shí)為理論基礎(chǔ),模擬人腦的神經(jīng)系統(tǒng)對復(fù)雜信息的處理機(jī)制的一種數(shù)學(xué)模型。該模型以并行分布的處理能力、高容錯(cuò)性、智能化和自學(xué)習(xí)等能力為特征,將信息的加工和存儲(chǔ)結(jié)合在一起,以其獨(dú)特的知識(shí)表示方式和智能化的自適應(yīng)學(xué)習(xí)能力,引起各學(xué)科領(lǐng)域的關(guān)注。它實(shí)際上是一個(gè)有大量簡單元件相互連接而成的復(fù)雜網(wǎng)絡(luò),具有高度的非線性,能夠進(jìn)行復(fù)雜的邏輯作和非線性關(guān)系實(shí)現(xiàn)的系統(tǒng)。 2.神經(jīng)網(wǎng)絡(luò)分類?
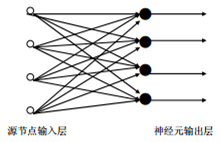
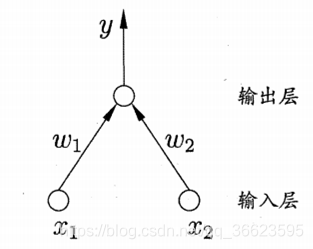
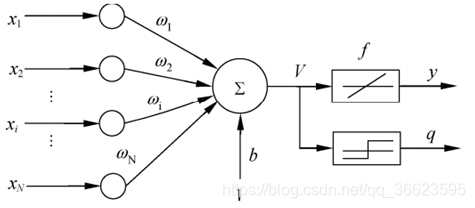
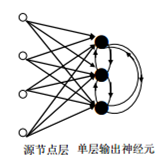
可以從不同的角度對人工神經(jīng)網(wǎng)絡(luò)進(jìn)行分類 從網(wǎng)絡(luò)性能角度可分為連續(xù)型與離散型網(wǎng)絡(luò)、確定性與隨機(jī)性網(wǎng)絡(luò)。從網(wǎng)絡(luò)結(jié)構(gòu)角度可為前向網(wǎng)絡(luò)與反饋網(wǎng)絡(luò)。從學(xué)習(xí)方式角度可分為有導(dǎo)師學(xué)習(xí)網(wǎng)絡(luò)和無導(dǎo)師學(xué)習(xí)網(wǎng)絡(luò)。按連續(xù)突觸性質(zhì)可分為一階線性關(guān)聯(lián)網(wǎng)絡(luò)和高階非線性關(guān)聯(lián)網(wǎng)絡(luò)。? 3. 單層神經(jīng)網(wǎng)絡(luò)所謂單層前向網(wǎng)絡(luò)是指擁有的計(jì)算節(jié)點(diǎn)(神經(jīng)元)是“單層”的,如圖 2所示。這里表示源節(jié)點(diǎn)個(gè)數(shù)的“輸入層”被看做一層神經(jīng)元,因?yàn)樵摗拜斎雽印辈痪哂袌?zhí)行計(jì)算的功能。
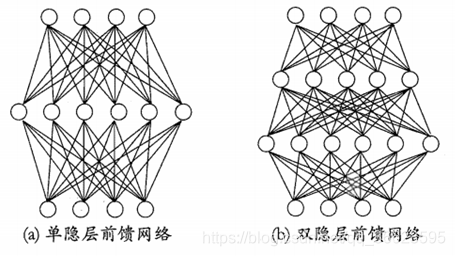
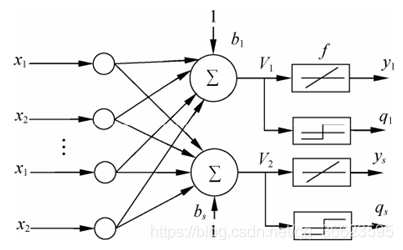
圖 2. 單層前向網(wǎng)絡(luò) ? ? 4.前饋神經(jīng)網(wǎng)絡(luò)前饋神經(jīng)網(wǎng)絡(luò)(feedforward neural network,F(xiàn)NN),如圖 3所示。
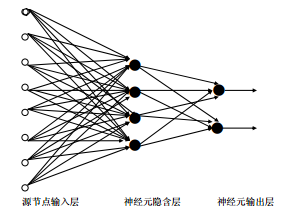
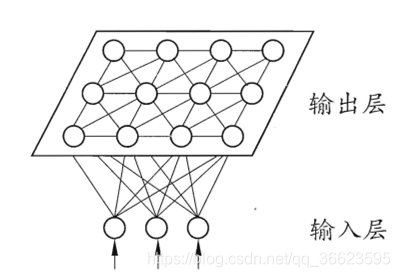
圖 3. 多層前饋神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)示意圖 多層前向網(wǎng)絡(luò)與單層前向網(wǎng)絡(luò)的區(qū)別在于:多層前向網(wǎng)絡(luò)含有一個(gè)或更多的隱含層,其中計(jì)算節(jié)點(diǎn)被相應(yīng)地稱為隱含神經(jīng)元或隱含單元,如圖 4所示
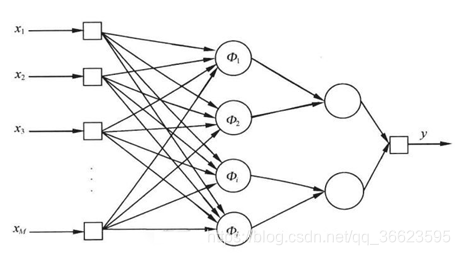
圖 4. 多層前向網(wǎng)絡(luò) ? 4.1 單層前饋神經(jīng)網(wǎng) 4.1.1 感知器感知器(Perceptron)由兩層神經(jīng)元組成。如圖 5所示,輸入層接收外界輸入信號(hào)后傳遞給輸出層,輸出層是M-P神經(jīng)元,也稱為“閾值邏輯單元”。 主要用于分類。 ? ?
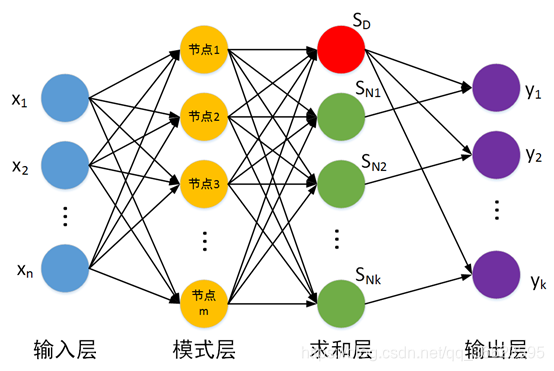
圖 5. 兩個(gè)輸入神經(jīng)元的感知機(jī)網(wǎng)絡(luò)結(jié)構(gòu)示意圖 優(yōu)點(diǎn):感知器模型簡單易于實(shí)現(xiàn)。 缺點(diǎn):僅能解決線性可分問題。 4.2 多層前饋神經(jīng)網(wǎng)絡(luò) 4.2.1 徑向基神經(jīng)網(wǎng)絡(luò)徑向基函數(shù) RBF 神經(jīng)網(wǎng)絡(luò)((Radial Basis Function,RBF)是一個(gè)只有一個(gè)隱藏層的三層前饋神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),它與前向網(wǎng)絡(luò)相比最大的不同在于,隱藏層得轉(zhuǎn)換函數(shù)是局部響應(yīng)的高斯函數(shù),而以前的前向網(wǎng)絡(luò)、轉(zhuǎn)換函數(shù)都是全局響應(yīng)的函數(shù)。由于這樣的不同,如果要實(shí)現(xiàn)同一個(gè)功能,RBF 網(wǎng)絡(luò)的神經(jīng)元個(gè)數(shù)就可能要比前向 BP 網(wǎng)絡(luò)的神經(jīng)元個(gè)數(shù)要多。 但是,RBF 網(wǎng)絡(luò)所需要的訓(xùn)練時(shí)間卻比前向 BP 網(wǎng)絡(luò)的要少。 主要功能:圖像處理,語音識(shí)別,時(shí)間系列預(yù)測,雷達(dá)原點(diǎn)定位,醫(yī)療診斷,錯(cuò)誤處理檢測,模式識(shí)別等。RBF網(wǎng)絡(luò)用得最多之處是用于分類,在分類之中,最廣的還是模式識(shí)別問題,次之是時(shí)間序列分析問題。 神經(jīng)網(wǎng)絡(luò)有很強(qiáng)的非線性擬合能力,可映射任意復(fù)雜的非線性關(guān)系,而且學(xué)習(xí)規(guī)則簡單,便于計(jì)算機(jī)實(shí)現(xiàn)。具有很強(qiáng)的魯棒性、記憶能力、非線性映射能力以及強(qiáng)大的自學(xué)習(xí)能力,因此有很大的應(yīng)用市場。 優(yōu)點(diǎn): 具有唯一最佳逼近的特性,且無局部極小問題存在。RBF神經(jīng)網(wǎng)絡(luò)具有較強(qiáng)的輸入和輸出映射功能,并且理論證明在前向網(wǎng)???? 絡(luò)中RBF網(wǎng)絡(luò)是完成映射功能的最優(yōu)網(wǎng)絡(luò)。網(wǎng)絡(luò)連接權(quán)值與輸出呈線性關(guān)系。分類能力好。學(xué)習(xí)過程收斂速度局限性: 最嚴(yán)重的問題是沒能力來解釋自己的推理過程和推理依據(jù)。不能向用戶提出必要的詢問,而且當(dāng)數(shù)據(jù)不充分的時(shí)候,神經(jīng)網(wǎng)絡(luò)就無法進(jìn)行工作。把一切問題的特征都變?yōu)閿?shù)字,把一切推理都變?yōu)閿?shù)值計(jì)算,其結(jié)果勢必是丟失信息。理論和學(xué)習(xí)算法還有待于進(jìn)一步完善和提高。隱層基函數(shù)的中心是在輸入樣本集中選取的, 這在許多情況下難以反映出系統(tǒng)真正的輸入輸出關(guān)系, 并且初始中心點(diǎn)數(shù)太多; 另外優(yōu)選過程會(huì)出現(xiàn)數(shù)據(jù)病態(tài)現(xiàn)象。4.2.1.1 廣義回歸神經(jīng)網(wǎng)絡(luò)(General Regression Neural Network,GPNN) 徑向基神經(jīng)元和線性神經(jīng)元可以建立廣義回歸神經(jīng)網(wǎng)絡(luò)(圖 6),它是徑RBF網(wǎng)絡(luò)的一種變化形式,經(jīng)常用于函數(shù)逼近。在某些方面比RBF網(wǎng)絡(luò)更具優(yōu)勢。GRNN與PNN一樣也是一個(gè)四層的網(wǎng)絡(luò)結(jié)構(gòu):輸入層、模式層、求和層、輸出層。
圖 6. 廣義回歸神經(jīng)網(wǎng)絡(luò) 優(yōu)點(diǎn):GRNN具有很強(qiáng)的非線性映射能力和學(xué)習(xí)速度,比RBF具有更強(qiáng)的優(yōu)勢,網(wǎng)絡(luò)最后普收斂于樣本量集聚較多的優(yōu)化回歸,樣本數(shù)據(jù)少時(shí),預(yù)測效果很好, 網(wǎng)絡(luò)還可以處理不穩(wěn)定數(shù)據(jù)。廣義回歸神經(jīng)網(wǎng)絡(luò)對x的回歸定義不同于徑向基函數(shù)的對高斯權(quán)值的最小二乘法疊加,他是利用密度函數(shù)來預(yù)測輸出。? 與PNN的區(qū)別:GRNN用于求解回歸問題,而PNN用于求解分類問題。? 4.2.1.2 概率神經(jīng)網(wǎng)絡(luò)(Probabilistic Neural Network,PNN) 徑向基神經(jīng)元和競爭神經(jīng)元還可以組成概率神經(jīng)網(wǎng)絡(luò)。PNN也是RBF的一種變化形式,結(jié)構(gòu)簡單訓(xùn)練快捷,特別適合于模式分類問題的解決。理論基礎(chǔ)是貝葉斯最小風(fēng)險(xiǎn)準(zhǔn)則,即是貝葉斯決策理論。 結(jié)構(gòu):由輸入層、隱含層、求和層、輸出層組成。也把隱含層稱為模式層,把求和層叫做競爭層,如圖 7所示。 ?
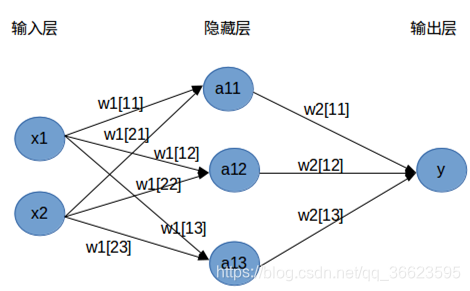
圖 7. PNN網(wǎng)絡(luò)結(jié)構(gòu) ? 第一層為輸入層,用于接收來自訓(xùn)練樣本的值,將數(shù)據(jù)傳遞給隱含層,神經(jīng)元個(gè)數(shù)與輸入向量長度相等。 第二層隱含層是徑向基層,每一個(gè)隱含層的神經(jīng)元節(jié)點(diǎn)擁有一個(gè)中心,該層接收輸入層的樣本輸入,計(jì)算輸入向量與中心的距離,最后返回一個(gè)標(biāo)量值,神經(jīng)元個(gè)數(shù)與輸入訓(xùn)練樣本個(gè)數(shù)相同。 ? 優(yōu)點(diǎn):訓(xùn)練容易,收斂速度快,從而非常適用于實(shí)時(shí)處理。在基于密度函數(shù)核估計(jì)的PNN網(wǎng)絡(luò)中,每一個(gè)訓(xùn)練樣本確定一個(gè)隱含層神經(jīng)元,神經(jīng)元的權(quán)值直接取自輸入樣本值。口可以實(shí)現(xiàn)任意的非線性逼近,用PNN網(wǎng)絡(luò)所形成的判決曲面與貝葉斯最優(yōu)準(zhǔn)則下的曲面非常接近。隱含層采用徑向基的非線性映射函數(shù),考慮了不同類別模式樣本的交錯(cuò)影響,具有很強(qiáng)的容錯(cuò)性。只要有充足的樣本數(shù)據(jù),概率神經(jīng)網(wǎng)絡(luò)都能收斂到貝葉斯分類器,沒有BP網(wǎng)絡(luò)的局部極小值問題。隱含層的傳輸函數(shù)可以選用各種用來估計(jì)概率密度的基函數(shù),且分類結(jié)果對基函數(shù)的形式不敏感。擴(kuò)充性能好。網(wǎng)絡(luò)的學(xué)習(xí)過程簡單,增加或減少類別模式時(shí)不需要重新進(jìn)行長時(shí)間的訓(xùn)練學(xué)習(xí)。各層神經(jīng)元的數(shù)目比較固定,因而易于硬件實(shí)現(xiàn)。 4.2.2 BP神經(jīng)網(wǎng)絡(luò)(Back Propagation,BP)強(qiáng)化多層神經(jīng)網(wǎng)絡(luò)的訓(xùn)練,必須引入算法,其中最成功的是誤差逆?zhèn)鞑ニ惴ǎ˙ack Propagation,簡稱BP算法)。BP算法不僅用于多層前饋神經(jīng)網(wǎng)絡(luò),還可以用于訓(xùn)練遞歸神經(jīng)網(wǎng)絡(luò)。解決了多層神經(jīng)網(wǎng)絡(luò)隱含層連接權(quán)學(xué)習(xí)問題,并在數(shù)學(xué)上給出了完整推導(dǎo)。人們把采用這種算法進(jìn)行誤差校正的多層前饋網(wǎng)絡(luò)稱為BP神經(jīng)網(wǎng)絡(luò)。 BP神經(jīng)網(wǎng)絡(luò)網(wǎng)絡(luò)主要四個(gè)方面的應(yīng)用: 函數(shù)逼近:用輸入向量和相應(yīng)的輸出向量訓(xùn)練一個(gè)網(wǎng)絡(luò)逼近一個(gè)函數(shù)。模式識(shí)別:用一個(gè)待定的輸出向量將它與輸入向量聯(lián)系起來。分類:把輸入向量所定義的合適方式進(jìn)行分類。數(shù)據(jù)壓縮:減少輸出向量維數(shù)以便于傳輸或存儲(chǔ)。優(yōu)點(diǎn) BP神經(jīng)網(wǎng)絡(luò)最主要的優(yōu)點(diǎn)是具有極強(qiáng)的非線性映射能力。BP神經(jīng)網(wǎng)絡(luò)具有對外界刺激和輸入信息進(jìn)行聯(lián)想記憶的能力。BP 神經(jīng)網(wǎng)絡(luò)通過預(yù)先存儲(chǔ)信息和學(xué)習(xí)機(jī)制進(jìn)行自適應(yīng)訓(xùn)練,可以從不完整的信息和噪聲干擾中恢復(fù)原始的完整信息。這種能力使其在圖像復(fù)原、語言處理、模式識(shí)別等方面具有重要應(yīng)用。BP 神經(jīng)網(wǎng)絡(luò)對外界輸入樣本有很強(qiáng)的識(shí)別與分類能力。由BP 神經(jīng)網(wǎng)絡(luò)具有優(yōu)化計(jì)算能力。BP神經(jīng)網(wǎng)絡(luò)本質(zhì)上是一個(gè)非線性優(yōu)化問題, 它可以在已知的約束條件下,尋找一組參數(shù)組合,使該組合確定的目標(biāo)函數(shù)達(dá)到最小。局限性 由于BP網(wǎng)絡(luò)訓(xùn)練中穩(wěn)定性要求學(xué)習(xí)效率很小,所以梯度下降法使得訓(xùn)練很慢。對于非線性系統(tǒng),選擇合適的學(xué)習(xí)率是一個(gè)重要的問題。在非線性網(wǎng)絡(luò)的誤差面比線性網(wǎng)絡(luò)的誤差面復(fù)雜得多,問題在于多層網(wǎng)絡(luò)中非線性傳遞函數(shù)有多個(gè)局部最優(yōu)解。網(wǎng)絡(luò)隱層神經(jīng)元的數(shù)目也對網(wǎng)絡(luò)有一定的影響。神經(jīng)元數(shù)目太少會(huì)造成網(wǎng)絡(luò)的不適性,而神經(jīng)元數(shù)目太多又會(huì)引起網(wǎng)絡(luò)的過適性。 4.2.3 全連接神經(jīng)網(wǎng)絡(luò)全連接神經(jīng)網(wǎng)絡(luò)(fully connected neural network),顧名思義,就是相鄰兩層之間任意兩個(gè)節(jié)點(diǎn)之間都有連接。全連接神經(jīng)網(wǎng)絡(luò)是最為普通的一種模型(比如和CNN相比),由于是全連接,所以會(huì)有更多的權(quán)重值和連接,因此也意味著占用更多的內(nèi)存和計(jì)算。 如定義了一個(gè)兩層的全連接神經(jīng)網(wǎng)絡(luò)。 ?
圖 8. 兩層全連接神經(jīng)網(wǎng)絡(luò) 4.2.4 卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks, CNN)卷積神經(jīng)網(wǎng)絡(luò)CNN(Convolutional Neural Networks, CNN)可以應(yīng)用在場景分類,圖像分類,現(xiàn)在還可以應(yīng)用到自然語言處理(NLP)方面的很多問題,比如句子分類等。 優(yōu)點(diǎn): 與傳統(tǒng)的多層感知器-MLP相比,CNN中卷積層的權(quán)值共享使網(wǎng)絡(luò)中可訓(xùn)練的參數(shù)邊少,降低了網(wǎng)絡(luò)模型復(fù)雜度,較少過擬合,從而獲得一個(gè)更好的泛化能力。CNN結(jié)構(gòu)中使用池化作使得模型中的神經(jīng)元個(gè)數(shù)大大的減少,對輸入空間的平移不變行也更有魯棒性CNN結(jié)構(gòu)的拓展性很強(qiáng),它可以采用很深的層數(shù),深度模型具有更強(qiáng)的表達(dá)能力,能夠處理更復(fù)雜的分類問題CNN的局部連接、權(quán)值共享和池化作比傳統(tǒng)的MLP具有更少的連接和參數(shù),更易于訓(xùn)練。 4.3 線性神經(jīng)網(wǎng)絡(luò)線性神經(jīng)網(wǎng)絡(luò)最典型的例子是自適應(yīng)線性元件(Adaptive Linear Element,Adaline)。自適應(yīng)線性元件 20 世紀(jì) 50 年代末由 Widrow 和 Hoff 提出,主要用途是通過線性逼近一個(gè)函數(shù)式而進(jìn)行模式聯(lián)想以及信號(hào)濾波、預(yù)測、模型識(shí)別和控制等。 ? 主要功能: 線性預(yù)測自適應(yīng)濾波噪聲抵消自適應(yīng)濾波系統(tǒng)辨識(shí)? 優(yōu)點(diǎn):線性神經(jīng)網(wǎng)絡(luò)只能反應(yīng)輸入和輸出樣本向量空間的線性映射關(guān)系。由于線性神經(jīng)網(wǎng)絡(luò)的誤差曲面是一個(gè)多維拋物面,所以在學(xué)習(xí)速率足夠小的情況下,對于基于最小二乘梯度下降原理進(jìn)行訓(xùn)練的神經(jīng)網(wǎng)絡(luò)總是可以找到一個(gè)最優(yōu)解。 局限性:線性神經(jīng)網(wǎng)絡(luò)的訓(xùn)練并不能一定總能達(dá)到零誤差。線性神經(jīng)網(wǎng)絡(luò)的訓(xùn)練性能要受到網(wǎng)絡(luò)規(guī)模、訓(xùn)練集大小的限制。 ? 線性神經(jīng)網(wǎng)絡(luò)與感知器的主要區(qū)別: 感知器的傳輸函數(shù)只能輸出兩種可能的值,而線性神經(jīng)網(wǎng)絡(luò)的輸出可以取任意值,其傳輸函數(shù)是線性函數(shù)。線性神經(jīng)網(wǎng)絡(luò)采用Widrow-Hoff 學(xué)習(xí)規(guī)則,即 LMS(Least Mean Square)算法來調(diào)整網(wǎng)絡(luò)的權(quán)值和偏置。線性神經(jīng)網(wǎng)絡(luò)在收斂的精度和速度上較感知器都有了較大提高,但其線性運(yùn)算規(guī)則決定了它只能解決線性可分的問題。線性神經(jīng)網(wǎng)絡(luò)在結(jié)構(gòu)上與感知器網(wǎng)絡(luò)非常相似,只是神經(jīng)元傳輸函數(shù)不同。? ?
圖 9. 線性神經(jīng)網(wǎng)絡(luò)的結(jié)構(gòu) ? 4.3.1 Madaline 神經(jīng)網(wǎng)絡(luò)若網(wǎng)絡(luò)中包含多個(gè)神經(jīng)元節(jié)點(diǎn),就能形成多個(gè)輸出,這種線性神經(jīng)網(wǎng)絡(luò)叫Madaline神經(jīng)網(wǎng)絡(luò)。 ?
圖 10. Madaline結(jié)構(gòu)圖 Madaline 可以用一種間接的方式解決線性不可分的問題,方法是用多個(gè)線性函數(shù)對區(qū)域進(jìn)行劃分,然后對各個(gè)神經(jīng)元的輸出做邏輯運(yùn)算。如圖所示,Madaline 用兩條直線實(shí)現(xiàn)了異或邏輯。 5.反饋型神經(jīng)神經(jīng)網(wǎng)絡(luò)反饋網(wǎng)絡(luò)是指在網(wǎng)絡(luò)中至少含有一個(gè)反饋回路的神經(jīng)網(wǎng)絡(luò)。反饋網(wǎng)絡(luò)可以包含一個(gè)單層神經(jīng)元,其中每個(gè)神經(jīng)元將自身的輸出信號(hào)反饋給其他所有神經(jīng)元的輸入反饋神經(jīng)網(wǎng)絡(luò)中神經(jīng)元不但可以接收其他神經(jīng)元的信號(hào),而且可以接收自己的反饋信號(hào)。和前饋神經(jīng)網(wǎng)絡(luò)相比,反饋神經(jīng)網(wǎng)絡(luò)中的神經(jīng)元具有記憶功能,在不同時(shí)刻具有不同的狀態(tài)。反饋神經(jīng)網(wǎng)絡(luò)中的信息傳播可以是單向也可以是雙向傳播,因此可以用一個(gè)有向循環(huán)圖或者無向圖來表示。 ? 5.1 遞歸神經(jīng)網(wǎng)絡(luò)(Recurrent neural network,RNN)與前饋神經(jīng)網(wǎng)絡(luò)不同"遞歸神經(jīng)網(wǎng)絡(luò)" (recurrent neural networks)允許網(wǎng)絡(luò)中出現(xiàn)環(huán)形結(jié)構(gòu),從而可讓一些神經(jīng)元的輸出反饋回來作為輸入信號(hào).這樣的結(jié)構(gòu)與信息反饋過程,使得網(wǎng)絡(luò)在 t 時(shí)刻的輸出狀態(tài)不僅與 t 時(shí)刻的輸入有關(guān),還與 t - 1 時(shí)刻的網(wǎng)絡(luò)狀態(tài)有關(guān),從而能處理與時(shí)間有關(guān)的動(dòng)態(tài)變化。 ? 5.1.1 Elman網(wǎng)絡(luò)?
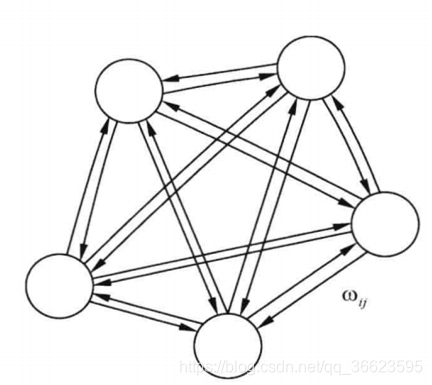
圖 11. Elman網(wǎng)絡(luò)結(jié)構(gòu) 基本的Elman伸進(jìn)網(wǎng)絡(luò)由輸入層、隱含層、連接層、輸出層組成。與BP網(wǎng)絡(luò)相比,在結(jié)構(gòu)上了多了一個(gè)連接層,用于構(gòu)成局部反饋。 特點(diǎn) 連接層的傳輸函數(shù)為線性函數(shù),但是多了一個(gè)延遲單元,因此連接層可以記憶過去的狀態(tài),并在下一時(shí)刻與網(wǎng)絡(luò)的輸入一起作為隱含層的輸入,使網(wǎng)絡(luò)具有動(dòng)態(tài)記憶功能,非常適合時(shí)間序列預(yù)測問題。輸出層和連接層的的傳遞函數(shù)為線性函數(shù),隱含層的傳遞函數(shù)則為某種非線性函數(shù),如Sigmoid函數(shù)。由于隱含層不但接收來自輸入層的數(shù)據(jù),還要接收連接層中存儲(chǔ)的數(shù)據(jù),因此對于相同的輸入數(shù)據(jù),不同時(shí)刻產(chǎn)生的輸出也可能不同。輸入層數(shù)據(jù)反映了信號(hào)的空域信息,而連接層延遲則反映了信號(hào)的時(shí)域信息,這是Elman網(wǎng)絡(luò)可以用于時(shí)域和空域模式識(shí)別的原因。? 主要應(yīng)用:Elman網(wǎng)絡(luò)主要用于信號(hào)檢測和預(yù)測方面 優(yōu)點(diǎn): 具有自組織、自學(xué)習(xí)的特征。在Elman神經(jīng)網(wǎng)絡(luò)模型中增加了隱層及輸出層節(jié)點(diǎn)的反饋,因而更進(jìn)一步地增強(qiáng)了網(wǎng)絡(luò)學(xué)習(xí)的精確性和容錯(cuò)性。利用Elman神經(jīng)網(wǎng)絡(luò)建立的網(wǎng)絡(luò)模型,對具有非線性時(shí)間序列特征的其它應(yīng)用領(lǐng)域都具有較好地應(yīng)用前景,它具有較強(qiáng)的魯棒性、良好的泛化能力、較強(qiáng)的通用性和客觀性,充分顯示出神經(jīng)網(wǎng)絡(luò)方法的優(yōu)越性和合理性,這種神經(jīng)網(wǎng)絡(luò)方法在其它領(lǐng)域預(yù)測和評(píng)價(jià)方面的使用將具有較好的實(shí)際應(yīng)用價(jià)值??? 5.2 Hopfield神經(jīng)網(wǎng)絡(luò)一種基于能量的模型(Energy Based Model,EBM)——可用作聯(lián)想存儲(chǔ)的互連網(wǎng)絡(luò),稱該模型為 Hopfield 網(wǎng)絡(luò)。 主要應(yīng)用:Hopfield網(wǎng)絡(luò)主要用于聯(lián)想記憶、聚類以及優(yōu)化計(jì)算等方面。 ? 根據(jù)其激活函數(shù)的不同,Hopfield 神經(jīng)網(wǎng)絡(luò)有兩種: 離散Hopfield 網(wǎng)絡(luò)(Discrete Hopfield Neural Network,DHNN)連續(xù)Hopfield 網(wǎng)絡(luò)(Continues Hopfield Neural Network,CHNN)。從圖 12中可以看出每個(gè)神經(jīng)元的輸出都成為其他神經(jīng)元的輸入,每個(gè)神經(jīng)元的輸入又都來自其他神經(jīng)元。神經(jīng)元輸出的數(shù)據(jù)經(jīng)過其他神經(jīng)元之后最終又反饋給自己。 ?
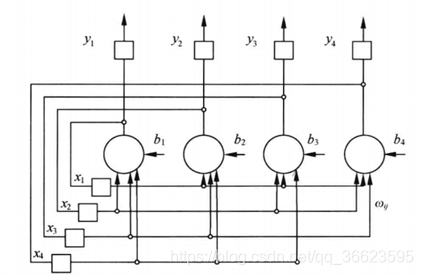
圖 12. Hopfield網(wǎng)絡(luò)的網(wǎng)狀結(jié)構(gòu) 局限性: 在具體神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)中要保證連接權(quán)矩陣是對稱的;在實(shí)際的神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)中, 總會(huì)存在信息的傳輸延遲, 這些延遲對神經(jīng)網(wǎng)絡(luò)的特性有影響。神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn)中的規(guī)模問題, 即集成度問題。 5.2.1 離散Hopfield網(wǎng)絡(luò)輸出值只能取0或1,分別表示神經(jīng)元的抑制和興奮狀態(tài)。如圖 13所示輸出神經(jīng)元的取值為0/1或-1/1。對于中間層,任意兩個(gè)神經(jīng)元間的連接權(quán)值為wij = wji ,神經(jīng)元的連接是對稱的。如果wij等于0,即神經(jīng)元自身無連接,則成為無自反饋的Hopfield網(wǎng)絡(luò),如果wij != 0,則成為有自反饋的Hopfield網(wǎng)絡(luò)。但是出于穩(wěn)定性考慮,一般避免使用有自反饋的網(wǎng)絡(luò)。 ?
圖 13. 離散Hopfield網(wǎng)絡(luò) 5.2.2 連續(xù)Hopfield網(wǎng)絡(luò)連續(xù)的Hopfield網(wǎng)絡(luò)結(jié)構(gòu)和離散的Hopfield網(wǎng)絡(luò)的結(jié)構(gòu)相同,不同之處在于傳輸函數(shù)不是階躍函數(shù)或符號(hào)函數(shù),而是S型的連續(xù)函數(shù),如sigmoid函數(shù)。每個(gè)神經(jīng)元由一個(gè)運(yùn)算放大器和相關(guān)的元件組成,其輸入一方面由輸出的反饋形成,另一方面也有以電流形式從外界連接過來的輸入。 ? 5.3 盒中腦模型(BSB) 盒中腦(Brain-State-in-a-Box,BSB)模型是一種節(jié)點(diǎn)之間存在橫向連接和節(jié)點(diǎn)自反饋的單層網(wǎng)絡(luò),可以用作自聯(lián)想最鄰近分類器,并可存儲(chǔ)任何模擬向量模式。該模型是一種神經(jīng)動(dòng)力學(xué)模型,可以看作是一個(gè)有幅度限制的正反饋系統(tǒng)。 ????? 特點(diǎn):BSB模型實(shí)際上是一種梯度下降法,在迭代的過程中,使得能量函數(shù)達(dá)到最小。 ? 6 自組織神經(jīng)網(wǎng)絡(luò) 6.1 競爭神經(jīng)網(wǎng)絡(luò) 競爭型學(xué)習(xí)(compaetitive learning)是神經(jīng)網(wǎng)絡(luò)的中一種常用的無監(jiān)督學(xué)習(xí)策略,在使用該策略時(shí),網(wǎng)絡(luò)的輸出神經(jīng)元相互競爭,每一時(shí)刻僅有一個(gè)獲勝的神經(jīng)元被激活,其他神經(jīng)元的狀態(tài)被抑制,中級(jí)機(jī)制也別稱為"勝者通吃"原則。 特點(diǎn): 競爭神經(jīng)網(wǎng)絡(luò)的顯著特點(diǎn)是它的輸出神經(jīng)元相互競爭以確定勝者,勝者指出哪一種原形模式最能代表輸入模式。Hamming 網(wǎng)絡(luò)是一個(gè)最簡單的競爭神經(jīng)網(wǎng)絡(luò),如圖 14所示。神經(jīng)網(wǎng)絡(luò)有一個(gè)單層的輸出神經(jīng)元,每個(gè)輸出神經(jīng)元都與輸入節(jié)點(diǎn)全相連,輸出神經(jīng)元之間全互連。從源節(jié)點(diǎn)到神經(jīng)元之間是興奮性連接,輸出神經(jīng)元之間橫向側(cè)抑制。?
圖 14. 最簡單的競爭神經(jīng)網(wǎng)絡(luò)-Hamming網(wǎng)絡(luò) 6.2 自適應(yīng)諧振理論網(wǎng)絡(luò)(Adaptive Resonance Theory,ART)自適應(yīng)諧振理論網(wǎng)絡(luò)(Adaptive Resonance Theory,ART)是一種競爭學(xué)習(xí)型神經(jīng)網(wǎng)絡(luò)。該網(wǎng)絡(luò)由比較層、識(shí)別層、識(shí)別閾和重要模塊構(gòu)成。其中,比較層負(fù)責(zé)接受輸入樣本,并將其傳遞給識(shí)別層神經(jīng)元。識(shí)別曾每個(gè)神經(jīng)元對應(yīng)一個(gè)模式類,神經(jīng)元數(shù)目可在訓(xùn)練過程中動(dòng)態(tài)增長以增加新的模式類。 ? 優(yōu)點(diǎn):課進(jìn)行增量學(xué)習(xí)(incremental Learning)或者在線學(xué)習(xí)(online learning) ? 6.3 自組織映射神經(jīng)網(wǎng)絡(luò)(Self-Organizing Map,SOM)SOM(Self-Organizing Map,自組織映射)網(wǎng)絡(luò),是一種競爭學(xué)習(xí)型的無監(jiān)督神經(jīng)網(wǎng)絡(luò),它能將高維輸入數(shù)據(jù)映射到低維空間(通常是二維),同時(shí)保持輸入數(shù)據(jù)在高維空間的拓?fù)浣Y(jié)構(gòu),即將高維空間中想死的樣本點(diǎn)映射到網(wǎng)絡(luò)輸出層中的鄰近神經(jīng)元。 如圖所示, SOM 網(wǎng)絡(luò)中的輸出層神經(jīng)元以矩陣方式排列在二維空間中,每個(gè)神經(jīng)元都擁有一個(gè)權(quán)向量,網(wǎng)絡(luò)在接收輸入向量后,將會(huì)確定輸出層獲勝神經(jīng)元,它決定了該輸入向量在低維空間中的位置. ?
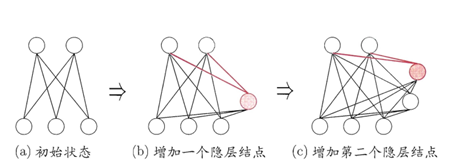
圖 15. SOM網(wǎng)絡(luò)結(jié)構(gòu) ? SOM的訓(xùn)練目標(biāo):每個(gè)輸出層神經(jīng)元找到合適的權(quán)向量,以達(dá)到保持拓?fù)浣Y(jié)構(gòu)的目的 ? SOM訓(xùn)練過程:在接收到一個(gè)訓(xùn)練樣本后.每個(gè)輸出層神經(jīng)局會(huì)計(jì)算該樣本與自身攜帶的權(quán)向量之間的距離,距離最近的神經(jīng)兀成為競爭獲勝者,稱為最佳匹配單元 (best matching unit). 然后,最佳匹配單元及其鄰近神經(jīng) 元的權(quán)向量將被調(diào)整,以使得這些權(quán)向量與當(dāng)前輸入樣本的距離縮小.這個(gè)過程不斷迭代,直至收斂. 與競爭神經(jīng)網(wǎng)絡(luò)的區(qū)別和聯(lián)系 聯(lián)系 非常類似,神經(jīng)元都具有競爭性,都采用無監(jiān)督的學(xué)習(xí)方式。同樣包含輸入層、輸出層兩層網(wǎng)絡(luò)區(qū)別 自組織映射網(wǎng)絡(luò)除了能學(xué)習(xí)輸入樣本的分布外,還能夠識(shí)別輸入向量的拓?fù)浣Y(jié)構(gòu)。自組織網(wǎng)絡(luò)中,單個(gè)神經(jīng)元對模式分類不起決定性的作用,需要靠多個(gè)神經(jīng)元協(xié)同作用完成。自組織神經(jīng)網(wǎng)絡(luò)輸出層引入網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu),以更好的模擬生物學(xué)中的側(cè)抑制現(xiàn)象。主要區(qū)別是競爭神經(jīng)網(wǎng)絡(luò)不存在核心層之前的相互連接,在更新權(quán)值時(shí)采用了勝者全得的方式,每次只更新獲勝神經(jīng)元對應(yīng)的連接權(quán)值;而自組織神經(jīng)網(wǎng)絡(luò)中,每個(gè)神經(jīng)元附近一定領(lǐng)域內(nèi)的神經(jīng)元也會(huì)得到更新,較遠(yuǎn)的神經(jīng)元?jiǎng)t不更新,從而使得幾何上相近的神經(jīng)元變得更相似。 7 結(jié)構(gòu)自適應(yīng)神經(jīng)網(wǎng)絡(luò)一般的神經(jīng)網(wǎng)絡(luò)模型通常假定 網(wǎng)絡(luò)結(jié)構(gòu)是事先固定的,訓(xùn)練的目的是利用訓(xùn)練樣本來確定合適的連接權(quán)、 闕值等參數(shù).與此不同, 結(jié)構(gòu)自適應(yīng)網(wǎng)絡(luò)則將網(wǎng)絡(luò)結(jié)構(gòu)也當(dāng)作學(xué)習(xí)的目標(biāo)之 一,并希望能在訓(xùn)練過程中找到最利合數(shù)據(jù)特點(diǎn)的網(wǎng)絡(luò)結(jié)構(gòu) ? 7.1 級(jí)聯(lián)相關(guān) (Cascade-Correlation) 網(wǎng)絡(luò)級(jí)聯(lián)相關(guān) (Cascade-Correlation) 網(wǎng)絡(luò)是結(jié)構(gòu)自適應(yīng)網(wǎng)絡(luò)的重要代表。級(jí)聯(lián)相關(guān)網(wǎng)絡(luò)有兩個(gè)主要成分"級(jí)聯(lián)"和"相關(guān)" 級(jí)聯(lián)是指建立層次連接的層級(jí)結(jié)構(gòu).在開始訓(xùn)練時(shí),網(wǎng)絡(luò)只有輸入層和輸出層,處于最小拓?fù)浣Y(jié)構(gòu);隨著訓(xùn)練的進(jìn)行,如圖 16所示,新的隱層神經(jīng)元逐漸加入,從而創(chuàng)建起層級(jí)結(jié)構(gòu). 當(dāng)新的隱層神經(jīng)元加入時(shí),其輸入端連接權(quán)值是凍結(jié)固 定的相關(guān)是指通過最大化新神經(jīng)元的輸出與網(wǎng)絡(luò)誤差之間的相關(guān)性(correlation)來訓(xùn)練相關(guān)的參數(shù). ?
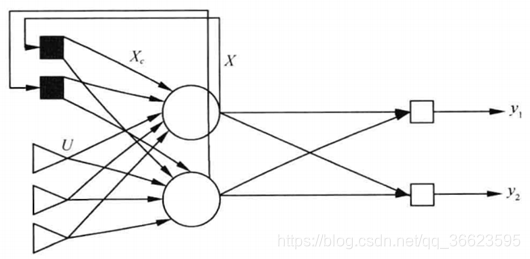
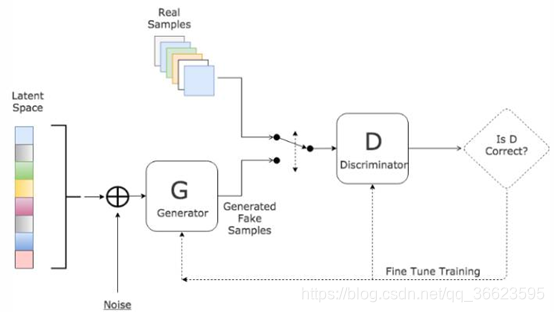
圖 16. 級(jí)聯(lián)相關(guān)網(wǎng)絡(luò)的訓(xùn)練過程。新的隱結(jié)點(diǎn)加入時(shí),紅色連接權(quán)通過最大化新結(jié)占的輸出與網(wǎng)終誤差之間的相關(guān)性來講行訓(xùn)練。 優(yōu)缺點(diǎn):與一般的前饋神經(jīng)網(wǎng)絡(luò)相比,級(jí)聯(lián)相關(guān)網(wǎng)絡(luò)無需設(shè)置網(wǎng)絡(luò)層數(shù)、隱層神經(jīng)元數(shù)目,且訓(xùn)練速度較快,但其在數(shù)據(jù)較小時(shí)易 陷入過擬合 ? 8.對抗神經(jīng)網(wǎng)絡(luò)GAN對抗神經(jīng)網(wǎng)絡(luò)其實(shí)是兩個(gè)網(wǎng)絡(luò)的組合,可以理解為一個(gè)網(wǎng)絡(luò)生成模擬數(shù)據(jù),另一個(gè)網(wǎng)絡(luò)判斷生成的數(shù)據(jù)是真實(shí)的還是模擬的。生成模擬數(shù)據(jù)的網(wǎng)絡(luò)要不斷優(yōu)化自己讓判別的網(wǎng)絡(luò)判斷不出來,判別的網(wǎng)絡(luò)也要不斷優(yōu)化自己讓判斷的更加精確。兩者的關(guān)系形成對抗,因此叫對抗神經(jīng)網(wǎng)絡(luò)。 結(jié)構(gòu):GAN由generator(生成模型)和discriminator(判別式模型)兩部分構(gòu)成。 二者結(jié)合之后,經(jīng)過大量次數(shù)的迭代訓(xùn)練會(huì)使generator盡可能模擬出以假亂真的樣本,而discrimator會(huì)有更精確的鑒別真?zhèn)螖?shù)據(jù)的能力,最終整個(gè)GAN會(huì)達(dá)到所謂的納什均衡,即discriminator對于generator的數(shù)據(jù)鑒別結(jié)果為正確率和錯(cuò)誤率各占50%。 ?
圖 17. GAN結(jié)構(gòu) generator網(wǎng)絡(luò):主要是從訓(xùn)練數(shù)據(jù)中產(chǎn)生相同分布的samples,對于輸入x,類別標(biāo)簽y,在生成模型中估計(jì)其聯(lián)合概率分布。discriminator網(wǎng)絡(luò):判斷輸入的是真實(shí)數(shù)據(jù)還是generator生成的數(shù)據(jù),即估計(jì)樣本屬于某類的條件概率分布。它采用傳統(tǒng)的監(jiān)督學(xué)習(xí)的方法。舉例:如果用到圖片生成上,則訓(xùn)練完成后,G可以從一段隨機(jī)數(shù)中生成逼真的圖像。G, D的主要功能是: G是一個(gè)生成式的網(wǎng)絡(luò),它接收一個(gè)隨機(jī)的噪聲z(隨機(jī)數(shù)),通過這個(gè)噪聲生成圖像D是一個(gè)判別網(wǎng)絡(luò),判別一張圖片是不是“真實(shí)的”。它的輸入?yún)?shù)是x,x代表一張圖片,輸出D(x)代表x為真實(shí)圖片的概率,如果為1,就代表100%是真實(shí)的圖片,而輸出為0,就代表不可能是真實(shí)的圖片?
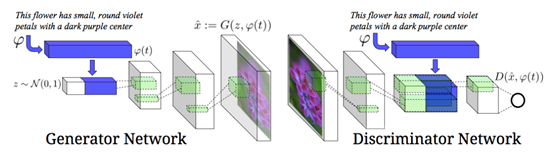
圖 18. 模型結(jié)構(gòu)如下圖所示。圖的左側(cè)是生成網(wǎng)絡(luò),右側(cè)是判別網(wǎng)絡(luò)。 ? 9 隨機(jī)神經(jīng)網(wǎng)絡(luò)隨機(jī)神經(jīng)網(wǎng)絡(luò)是對神經(jīng)網(wǎng)絡(luò)引入隨機(jī)機(jī)制,認(rèn)為神經(jīng)元是按照概率的原理進(jìn)行工作的,這就是說,每個(gè)神經(jīng)元的興奮或抑制具有隨機(jī)性,其概率取決于神經(jīng)元的輸入。 ? 9.1 玻爾茲曼機(jī)(Boltzmann)在Hopfield網(wǎng)絡(luò)中引入隨機(jī)機(jī)制,提出了Boltzmann機(jī),這是第一個(gè)由統(tǒng)計(jì)力學(xué)導(dǎo)出的多層學(xué)習(xí)機(jī),可以對給定數(shù)據(jù)集的固有概率分布進(jìn)行建模,可以用于模式識(shí)別等領(lǐng)域。得此名的原因是,它將模擬退火算法反復(fù)更新網(wǎng)絡(luò)狀態(tài),網(wǎng)絡(luò)狀態(tài)出現(xiàn)的概率服從Boltzmann分布,即最下能量狀態(tài)的概率最高,能量越大,出現(xiàn)的概率越低。 由隨機(jī)神經(jīng)元組成,神經(jīng)元分為可見神經(jīng)元和隱藏神經(jīng)元,與輸入/輸出有關(guān)的神經(jīng)元為可見神經(jīng)元,隱藏神經(jīng)元需要通過可見神經(jīng)元才能與外界交換信息。 特點(diǎn):Boltzmann機(jī)學(xué)習(xí)的主要目的在于產(chǎn)生一個(gè)神經(jīng)網(wǎng)絡(luò),根據(jù)Bolazmann分布對輸入模型進(jìn)行正確建模,訓(xùn)練挽留過的權(quán)值,當(dāng)其導(dǎo)出的可見神經(jīng)元狀態(tài)的概率分布和被約束時(shí)完全相同時(shí),訓(xùn)練就完成了。 訓(xùn)練過程Boltzmann 機(jī)的訓(xùn)練過程:將每個(gè)訓(xùn)練樣本視為一個(gè)狀態(tài)向量,使其出現(xiàn)的概率盡可能大.標(biāo)準(zhǔn)的 Boltzmann 機(jī)是一個(gè)全連接圖,訓(xùn)練網(wǎng)絡(luò)的復(fù)雜度很高,這使其難以用于解決現(xiàn)實(shí)任務(wù). 現(xiàn)實(shí)中 常采用受限Boltzmann機(jī)(Restricted Boltzmann Machine,簡稱 RBM) . 如圖 19所示,受限 Boltzmann 機(jī)僅保留顯層與隱層之間的連接 從而將 Boltzmann 機(jī)結(jié)構(gòu)由完全圖簡化為二部圖。 ?
圖 19. Boltzmann機(jī)與受限Boltzmann機(jī) |


【本文地址】
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |