| [python]LDA模型使用流程及代碼 | 您所在的位置:網(wǎng)站首頁(yè) › 85年屬牛的啥命 › [python]LDA模型使用流程及代碼 |
[python]LDA模型使用流程及代碼
|
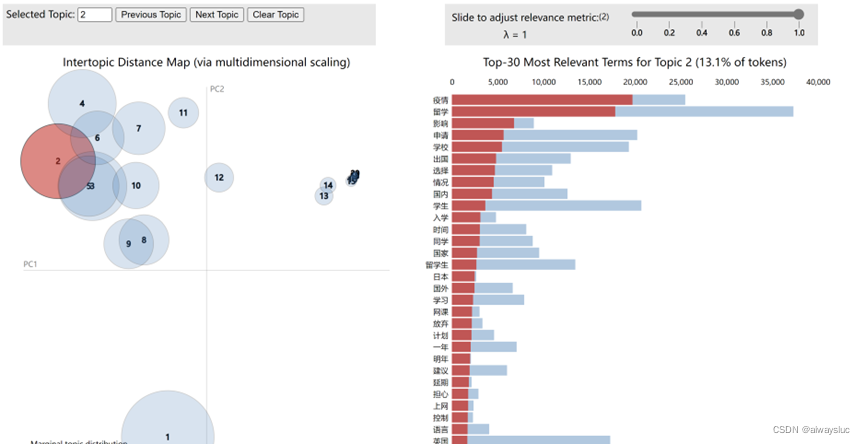
目錄 數(shù)據(jù)預(yù)處理 去除停用詞 構(gòu)建LDA模型 可視化——pyLDAvis ?主題個(gè)數(shù)確認(rèn) 困惑度計(jì)算 一致性得分 數(shù)據(jù)預(yù)處理該步驟可自行處理,用excel也好,用python也罷,只要將待分析文本處理為csv或txt存儲(chǔ)格式即可。注意:一條文本占一行 例如感想.txt: 我喜歡吃漢堡 小明喜歡吃螺螄粉 螺螄粉外賣好貴 以上句子來源于吃完一個(gè)漢堡還想再點(diǎn)碗螺螄粉,但外賣好貴從而選擇放棄的我 去除停用詞 import re import jieba as jb def stopwordslist(filepath): stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()] return stopwords # 對(duì)句子進(jìn)行分詞 def seg_sentence(sentence): sentence = re.sub(u'[0-9\.]+', u'', sentence) #jb.add_word('詞匯') # 這里是加入自定義的詞來補(bǔ)充jieba詞典 sentence_seged = jb.cut(sentence.strip()) stopwords = stopwordslist('自己搜來的停用詞表.txt') # 這里加載停用詞的路徑 outstr = '' for word in sentence_seged: if word not in stopwords and word.__len__()>1: if word != '\t': outstr += word outstr += " " return outstr inputs = open('感想.txt', 'r', encoding='utf-8') outputs = open('感想分詞.txt', 'w',encoding='utf-8') for line in inputs: line_seg = seg_sentence(line) # 這里的返回值是字符串 outputs.write(line_seg + '\n') outputs.close() inputs.close()該步驟生成感想分詞.txt: 我 喜歡 吃 漢堡 小明 喜歡 吃 螺螄粉 螺螄粉 外賣 好貴 句子 來源于 吃完 一個(gè) 漢堡 ?再點(diǎn)碗 螺螄粉?外賣 好貴 ?選擇 放棄? 構(gòu)建LDA模型假設(shè)主題個(gè)數(shù)設(shè)為4個(gè)(num_topics的參數(shù)) import codecs from gensim import corpora from gensim.models import LdaModel from gensim.corpora import Dictionary train = [] fp = codecs.open('感想分詞.txt','r',encoding='utf8') for line in fp: if line != '': line = line.split() train.append([w for w in line]) dictionary = corpora.Dictionary(train) corpus = [dictionary.doc2bow(text) for text in train] lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=100) # num_topics:主題數(shù)目 # passes:訓(xùn)練倫次 # num_words:每個(gè)主題下輸出的term的數(shù)目 for topic in lda.print_topics(num_words = 20): termNumber = topic[0] print(topic[0], ':', sep='') listOfTerms = topic[1].split('+') for term in listOfTerms: listItems = term.split('*') print(' ', listItems[1], '(', listItems[0], ')', sep='') 可視化——pyLDAvis import pyLDAvis.gensim_models '''插入之前的代碼片段''' import codecs from gensim import corpora from gensim.models import LdaModel from gensim.corpora import Dictionary train = [] fp = codecs.open('感想分詞.txt','r',encoding='utf8') for line in fp: if line != '': line = line.split() train.append([w for w in line]) dictionary = corpora.Dictionary(train) corpus = [dictionary.doc2bow(text) for text in train] lda = LdaModel(corpus=corpus, id2word=dictionary, num_topics=4, passes=100) # num_topics:主題數(shù)目 # passes:訓(xùn)練倫次 # num_words:每個(gè)主題下輸出的term的數(shù)目 for topic in lda.print_topics(num_words = 20): termNumber = topic[0] print(topic[0], ':', sep='') listOfTerms = topic[1].split('+') for term in listOfTerms: listItems = term.split('*') print(' ', listItems[1], '(', listItems[0], ')', sep='') d=pyLDAvis.gensim_models.prepare(lda, corpus, dictionary) ''' lda: 計(jì)算好的話題模型 corpus: 文檔詞頻矩陣 dictionary: 詞語空間 ''' #pyLDAvis.show(d) #展示在瀏覽器 # pyLDAvis.displace(d) #展示在notebook的output cell中 pyLDAvis.save_html(d, 'lda_pass4.html')這樣就會(huì)生成看起來很炫酷的圖啦(只是示例):
計(jì)算不同參數(shù)下結(jié)果的 Perlexity(困惑度)和 Coherence score(一致性評(píng)分),選擇困惑度最低且一致性評(píng)分最高的參數(shù)值作為最終參數(shù)設(shè)定。 困惑度計(jì)算 import gensim from gensim import corpora, models import matplotlib.pyplot as plt import matplotlib from nltk.tokenize import RegexpTokenizer from nltk.stem.porter import PorterStemmer # 準(zhǔn)備數(shù)據(jù) PATH = "感想分詞.txt" #已經(jīng)進(jìn)行了分詞的文檔(如何分詞前面的文章有介紹) file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') data_set=[] #建立存儲(chǔ)分詞的列表 for i in range(len(file_object2)): result=[] seg_list = file_object2[i].split() #讀取沒一行文本 for w in seg_list :#讀取每一行分詞 result.append(w) data_set.append(result) print(data_set) #輸出所有分詞列表 dictionary = corpora.Dictionary(data_set) # 構(gòu)建 document-term matrix corpus = [dictionary.doc2bow(text) for text in data_set] Lda = gensim.models.ldamodel.LdaModel # 創(chuàng)建LDA對(duì)象 #計(jì)算困惑度 def perplexity(num_topics): ldamodel = Lda(corpus, num_topics=num_topics, id2word = dictionary, passes=50) #passes為迭代次數(shù),次數(shù)越多越精準(zhǔn) print(ldamodel.print_topics(num_topics=num_topics, num_words=20)) #num_words為每個(gè)主題下的詞語數(shù)量 print(ldamodel.log_perplexity(corpus)) return ldamodel.log_perplexity(corpus) # 繪制困惑度折線圖 x = range(1,20) #主題范圍數(shù)量 y = [perplexity(i) for i in x] plt.plot(x, y) plt.xlabel('主題數(shù)目') plt.ylabel('困惑度大小') plt.rcParams['font.sans-serif']=['SimHei'] matplotlib.rcParams['axes.unicode_minus']=False plt.title('主題-困惑度變化情況') plt.show()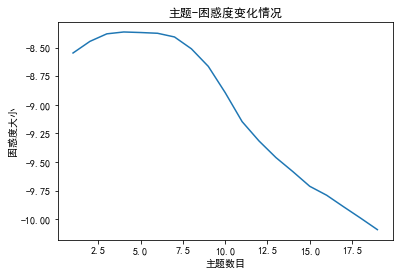
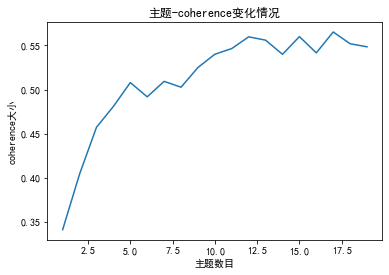
? 一致性得分 import gensim from gensim import corpora, models import matplotlib.pyplot as plt import matplotlib from nltk.tokenize import RegexpTokenizer from nltk.stem.porter import PorterStemmer import gensim import gensim.corpora as corpora from gensim.utils import simple_preprocess from gensim.models import CoherenceModel # 準(zhǔn)備數(shù)據(jù) PATH = "感想分詞.txt" #已經(jīng)進(jìn)行了分詞的文檔(如何分詞前面的文章有介紹) file_object2=open(PATH,encoding = 'utf-8',errors = 'ignore').read().split('\n') data_set=[] #建立存儲(chǔ)分詞的列表 for i in range(len(file_object2)): result=[] seg_list = file_object2[i].split() #讀取沒一行文本 for w in seg_list :#讀取每一行分詞 result.append(w) data_set.append(result) print(data_set) #輸出所有分詞列表 dictionary = corpora.Dictionary(data_set) # 構(gòu)建 document-term matrix corpus = [dictionary.doc2bow(text) for text in data_set] Lda = gensim.models.ldamodel.LdaModel # 創(chuàng)建LDA對(duì)象 def coherence(num_topics): ldamodel = Lda(corpus, num_topics=num_topics, id2word = dictionary, passes=50) #passes為迭代次數(shù),次數(shù)越多越精準(zhǔn) coherence_model_lda = CoherenceModel(model=ldamodel, texts=data_set, dictionary=dictionary, coherence='c_v') coherence_lda = coherence_model_lda.get_coherence() print('\nCoherence Score: ', coherence_lda) return coherence_lda # 繪制困惑度折線圖 x = range(1,20) #主題范圍數(shù)量 y = [coherence(i) for i in x] plt.plot(x,y) plt.xlabel('主題數(shù)目') plt.ylabel('coherence大小') plt.rcParams['font.sans-serif']=['SimHei'] matplotlib.rcParams['axes.unicode_minus']=False plt.title('主題-coherence變化情況') plt.show()
整個(gè)流程就大致是這樣啦!有問題歡迎一起交流!!
? |

【本文地址】
公司簡(jiǎn)介
聯(lián)系我們
| 今日新聞 |
| 推薦新聞 |
| 專題文章 |